ETL mit Kestra - Spender:innenwanderungen über die Zeit
Wir orchestrieren einen ETL-Prozess (Extract, Transform & Load) mit Kestra um die Frage zu beantworten, wie sich Spender:innentypen über die Zeit entwickeln. Dazu aggregieren wir Daten über die CiviCRM API und laden sie täglich in eine Datenbank, um die Entwicklung mit einem Line-Chart zu visualisieren.
🧹 daten-organisieren: CiviCRM API Explorer & Neon; CiviCRM API & Kestra
🔢 daten-auswerten: Metabase
📊 daten-visualisieren: Metabase
Voraussetzungen
- Account bei Neon
- API-Token für eine CiviCRM-Instanz
- Kestra-Instanz oder ein Abonnement des Kestra SaaS
- Metabase-Instanz oder ein Abonnement des Metabase SaaS
- Benutzerdefiniertes Datenfeld Donor Type in CiviCRM
Anleitung
Dieser Ansatz besteht aus 5 Komponenten , die wir nacheinander vorbereiten.
A: Erweiterung der CiviCRM Datenfelder
Wie hier beschrieben, benötigen wir ein neues benutzerdefiniertes Datenfeld, das den Typ einer spendenden Person erfasst. Für Demonstrationszwecke halten wir es simpel und legen das Feld Donor Type als Auswahlliste mit den Optionen One Time Donor, Monthly Donor und Past Donor an. Die Benennung ist dabei beliebig veränderbar und es könnten auch mehr Optionen genutzt werden.
Für unseren Test erstellen wir programmatisch Testdaten mit diesem Datenfeld. In der Realität müsst ihr dieses neue Feld jedoch in eure Erfassung von Kontakten integrieren, oder die Information anderweitig erfassen. Eine Option ist zum Beispiel die Nutzung von Gruppen für Kontakte. Auf Englisch ist dies hier dokumentiert. Ihr könntet Gruppen mit Kriterien wie ist zu einer Contribution zugeordnet anlegen.
B: Anlegen einer Tabelle in der Managed Datenbank (Neon)
Option 1: GUI
Erstelle eine neue Tabelle (wie hier beschrieben):
- Gebe der Tabelle den Namen
spendende_typen_agg - Füge die Spalte
timestampmit dem Datentyptimestampund dem ConstraintNot nullhinzu - Füge für jeden Spender:innentyp eine Spalte hinzu (z.B.
nicht_spendend,einmalig,monatlich,ehemalig) - Wähle für diese Spalten den Datentyp
integerund den ConstraintNot nullaus
Constraints
Constraints
Constraints sind Regeln, die die Datenintegrität und -konsistenz gewährleisten, indem sie festlegen, welche Daten wie in Tabellen gespeichert werden dürfen. Sie dienen als Datenvalidierungsprüfungen auf Ebene der Datenbank.
Option 2: SQL-Editor
Die Tabelle lässt sich im SQL-Editor von Neon durch das Ausführen des folgenden Codes erstellen:
CREATE TABLE IF NOT EXISTS "spendende_typen_agg" (
"id" integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY (
sequence name "spendende_typen_agg_id_seq"
),
"timestamp" timestamp NOT NULL,
"nicht_spendend" integer NOT NULL,
"monatlich" integer NOT NULL,
"einmalig" integer NOT NULL,
"ehemalig" integer NOT NULL
);
Diesen und anderen SQL-Code findet ihr auch im Repository in dem Ordner supporting_code/sql.
C: Datenmodellierung im API-Explorer von CiviCRM
Navigiert zum API Explorer und wählt als Entität Contact, sowie als Aktion get aus. Hier besteht die Datenmodellierung nun aus einer Aggregation nach dem Typ der spendenden Person.
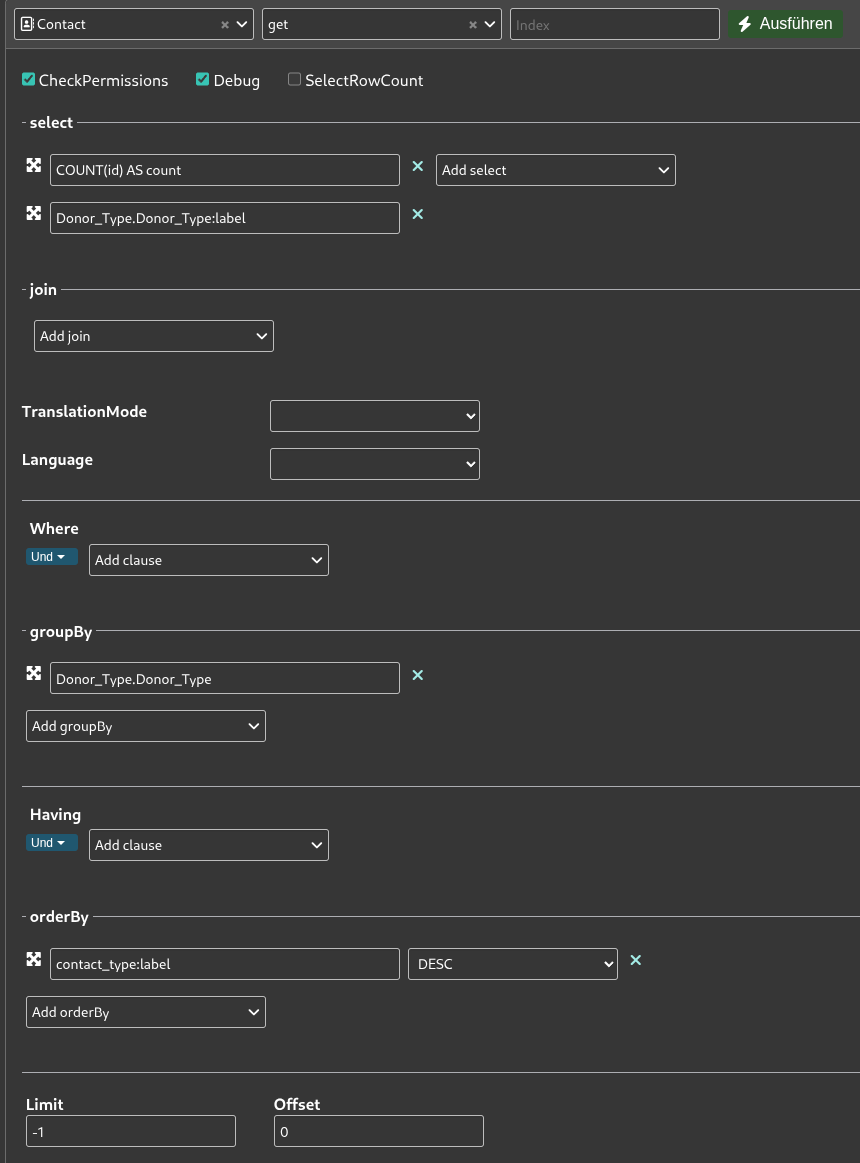
Konfiguriert die API-Anfrage so wie in dem Screenshot oben:
- Wählt unter select die Felder
COUNT(id) AS countundDonor_Type.Donor_Type:labelaus - Nutzt die groupBy Funktion, um die Reihen nach
Donor_Type.Donor_Typezu gruppieren - Sortiert die Ergebnisse unter orderBy nach
contact_type:labelin absteigender Reihenfolge (DESC)
Nach diesen Schritten könnt ihr bereits den Request Body weiter unten unter REST kopieren. Dies sollte in etwa so aussehen:
params=%7B%22select%22%3A%5B%22COUNT%28id%29%20AS%20count%22%2C%22Donor_Type.Donor_Type%3Alabel%22%5D%2C%22orderBy%22%3A%7B%22contact_type%3Alabel%22%3A%22DESC%22%7D%2C%22groupBy%22%3A%5B%22Donor_Type.Donor_Type%22%5D%7D
D: Anlegen des Flows in Kestra
Erstellt einen neuen Workflow auf eurer Kestra-Instanz. Der vollständige Flow als YAML:
id: civicrm_donor_type_count_warehouse
namespace: company.team
tasks:
- id: request
type: io.kestra.plugin.core.http.Request
uri: "{{ secret('CIVICRM_API_URI') }}"
headers:
X-Civi-Auth: "Bearer {{ secret('CIVICRM_API_TOKEN') }}"
method: POST
contentType: application/x-www-form-urlencoded
body: |
params=%7B%22select%22%3A%5B%22COUNT%28id%29%20AS%20count%22%2C%22Donor_Type.Donor_Type%3Alabel%22%5D%2C%22orderBy%22%3A%7B%22contact_type%3Alabel%22%3A%22DESC%22%7D%2C%22groupBy%22%3A%5B%22Donor_Type.Donor_Type%22%5D%7D
- id: to_rows
type: io.kestra.plugin.transform.jsonata.TransformValue
from: "{{ outputs.request.body }}"
expression: |
[{
"nicht_spendend": $sum(values[$."Donor_Type.Donor_Type:label" = null].count),
"ehemalig": $sum(values[$."Donor_Type.Donor_Type:label" = "Past Donor"].count),
"monatlich": $sum(values[$."Donor_Type.Donor_Type:label" = "Monthly Donor"].count),
"einmalig": $sum(values[$."Donor_Type.Donor_Type:label" = "One Time Donor"].count)
}]
- id: insert_agg
type: io.kestra.plugin.jdbc.postgresql.Query
url: "jdbc:postgresql://{{ secret('CIVICRM_NEON_WAREHOUSE_HOST') }}:5432/main"
username: "{{ secret('CIVICRM_NEON_WAREHOUSE_USER') }}"
password: "{{ secret('CIVICRM_NEON_WAREHOUSE_PW') }}"
sql: |
INSERT INTO spendende_typen_agg(timestamp, nicht_spendend, ehemalig, monatlich, einmalig)
SELECT NOW(), nicht_spendend, ehemalig, monatlich, einmalig
FROM jsonb_to_recordset('{{ outputs.to_rows.value }}'::jsonb)
AS t(nicht_spendend int, ehemalig int, monatlich int, einmalig int);
fetchType: NONE
triggers:
- id: schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: 0 0 * * 0
Diesen und andere Kestra-Flows findet ihr auch im Repository in dem Ordner supporting_code/kestra_flows
1. Knoten für die API-Anfrage
Der erste Knoten enthält die API-Anfrage:
- Fügt unter
uriam Anfang die URL eurer Instanz ein. Im API Explorer unter dem Reiter REST ist dies auch als VariableCRM_URLdefiniert - Fügt euer API-Token als Secret ein (siehe oben)
- Im Feld
bodyfügt ihr den im API-Explorer generierten Body ein (siehe oben)
Ein Beispiel-Output der API-Anfrage ist:
{
"values": [
{"count": 22, "Donor_Type.Donor_Type:label": null},
{"count": 76, "Donor_Type.Donor_Type:label": "One Time Donor"},
{"count": 117, "Donor_Type.Donor_Type:label": "Past Donor"},
{"count": 91, "Donor_Type.Donor_Type:label": "Monthly Donor"}
],
"entity": "Contact",
"action": "get",
"debug": null,
"version": 4,
"count": 4,
"countFetched": 4
}
2. Knoten für die Verarbeitung mit JSONata
JSONata ist eine Sprache für die Abfrage und Verarbeitung von JSON-Daten. In diesem Fall transformieren wir die API-Antwort in ein Format, das sich direkt in unsere Datenbank-Tabelle einfügen lässt.
Der JSONata-Knoten nutzt die Expression:
[{
"nicht_spendend": $sum(values[$."Donor_Type.Donor_Type:label" = null].count),
"ehemalig": $sum(values[$."Donor_Type.Donor_Type:label" = "Past Donor"].count),
"monatlich": $sum(values[$."Donor_Type.Donor_Type:label" = "Monthly Donor"].count),
"einmalig": $sum(values[$."Donor_Type.Donor_Type:label" = "One Time Donor"].count)
}]
So funktioniert die Expression:
- Filtern:
values[$."Donor_Type.Donor_Type:label" = "Past Donor"]durchsucht das Arrayvaluesund filtert nur die Objekte, deren Label dem gesuchten Typ entspricht - Extrahieren:
.countgreift auf dascount-Feld der gefilterten Objekte zu - Aggregieren:
$sum()summiert alle gefundenen Werte (relevant wenn mehrere Matches existieren) - Strukturieren: Die eckigen Klammern
[]erstellen ein Array mit einem einzelnen Objekt, dessen Keys (nicht_spendend,ehemalig, etc.) den Spaltennamen in unserer Datenbank entsprechen
Beispiel-Output:
{ "ehemalig": 117, "einmalig": 76, "monatlich": 91, "nicht_spendend": 22 }
3. Knoten für das Laden der Daten in die Managed Datenbank
Dieser letzte Knoten ist für das Laden der Daten in die Managed Datenbank auf Neon, unser Data Warehouse, zuständig:
- Legt zunächst ein Secret für Postgres an. Die notwendigen Informationen findet ihr in der Neon Konsole
- Konfiguriert den Knoten so, dass die transformierten Daten als neue Zeile mit dem aktuellen Timestamp in die Tabelle
spendende_typen_aggeingefügt werden
Wenn ihr Kestra selbst hostet, könnt ihr API Tokens etc. als Secrets über Environment Variables anlegen.
Die SQL-Query im Detail:
INSERT INTO spendende_typen_agg(timestamp, nicht_spendend, ehemalig, monatlich, einmalig)
SELECT NOW(), nicht_spendend, ehemalig, monatlich, einmalig
FROM jsonb_to_recordset('{{ outputs.to_rows.value }}'::jsonb)
AS t(nicht_spendend int, ehemalig int, monatlich int, einmalig int);
So funktioniert die Query:
INSERT INTO spendende_typen_agg(...): Definiert in welche Tabelle und Spalten die Daten eingefügt werdenNOW(): Erzeugt den aktuellen Timestamp für die Zeile, sodass wir später nachvollziehen können, wann diese Daten erfasst wurdenjsonb_to_recordset(...): Konvertiert das JSON-Objekt aus dem vorherigen Knoten in eine relationale Tabellenstruktur'{{ outputs.to_rows.value }}': Kestra-Syntax um auf den Output desto_rows-Knotens zuzugreifenAS t(nicht_spendend int, ...): Definiert das Schema der temporären Tabelletmit den entsprechenden Spaltentypen
Regelmäßige Snapshots
Regelmäßige Snapshots
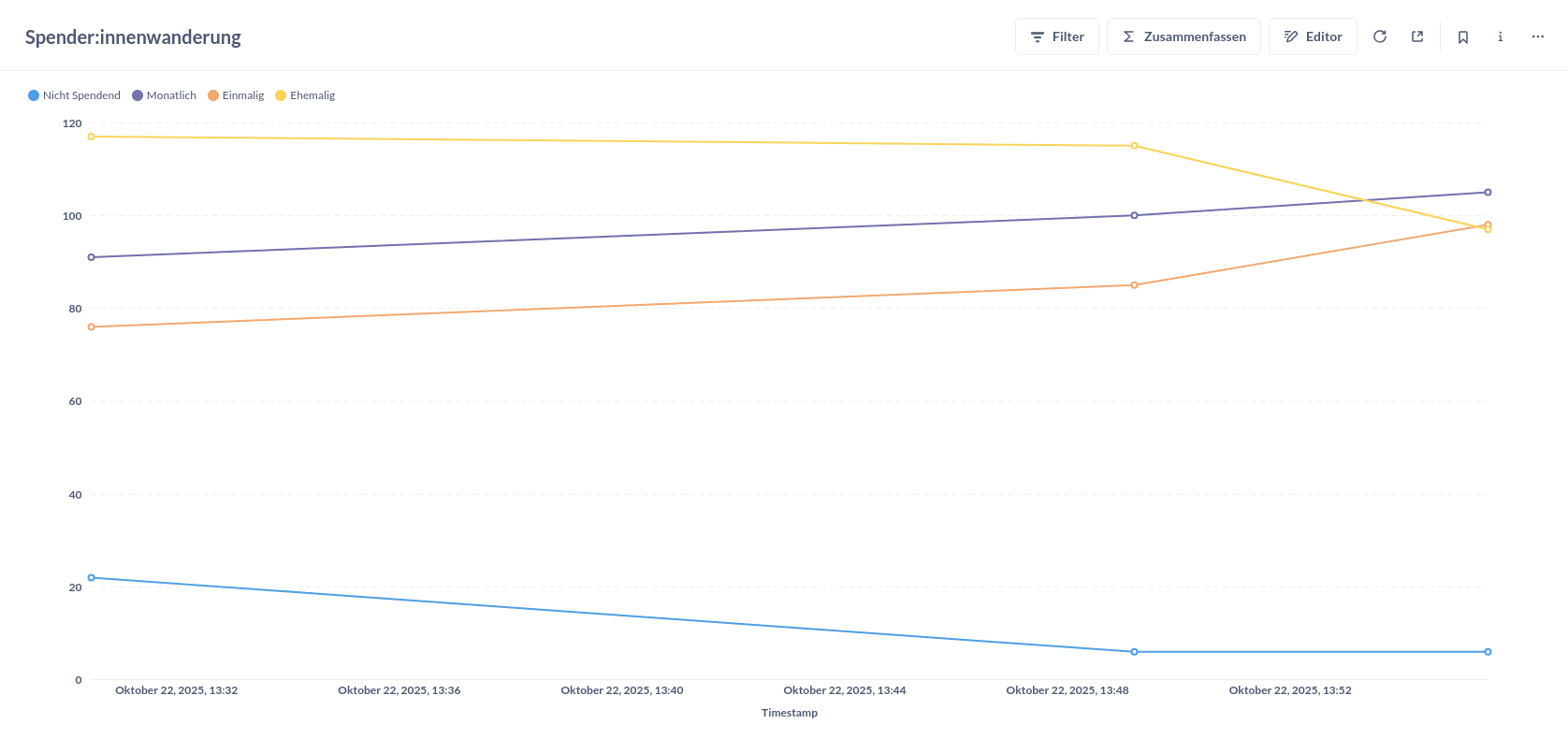
In den Begriffen des Data Engineering vollziehen wir hier regelmäßige Snapshots. Bei jeder Ausführung wird eine neue Zeile mit den aktuellen Zählungen der verschiedenen Spender:innentypen angelegt. So können wir die Entwicklung über die Zeit nachvollziehen.
H: Visualisierung in Metabase
-
Verbindet wie hier beschrieben die Datenbank mit Metabase. An die notwendigen Informationen kommt ihr ähnlich wie beim Anlegen der Postgres Credentials für den letzten Knoten des Workflows
-
Lest euch den Abschnitt zu Visualisierung in Metabase durch. Die Visualisierung ist ein Line-Chart, der die Entwicklung der verschiedenen Spender:innentypen mit jeweils einer Linie über die Zeit darstellt. Nutzt die Spalte
timestampfür die X-Achse und die verschiedenen Typen-Spalten für die Y-Achse
Fazit
Es lässt sich ein ähnliches Fazit wie für den Abschnitt zu ETL mit n8n ziehen. Ein Unterschied ist die Erforderniss der Erweiterung der CiviCRM-Datenfelder, um das Informationen zu Spender:innen zu erfassen.
Kestra als Workflow Tool benötigt im Vergleich zu n8n deutlich mehr technische Skills. Ein wesentlicher Vorteil ist die Versionierbarkeit: Flows werden als YAML-Dateien definiert und können in Git-Repositories gespeichert werden, was Code Reviews, Knowledge Transfer und Zusammenarbeit im Team erheblich erleichtert. Zudem bietet Kestra deutlich mehr Flexibilität – die Code-Umgebung ist erweiterbar, und es stehen umfangreiche Transformationsmöglichkeiten zur Verfügung.