Einführung
Kontakte, Spenden, Mitglieder oder Events managen, Kampagnen durchführen, mit den eigenen Zielgruppen kommunizieren oder Daten zur Wirkungsmessung erheben: Immer mehr zivilgesellschaftliche Organisationen nutzen die Open-Source-Software CiviCRM. So sind für viele Mitarbeiter*innen und engagierte CiviCRM-Daten die Grundlage ihrer täglichen inhaltlichen Arbeit geworden.
Doch wie können zivilgesellschaftliche Akteur*innen in CiviCRM gesammelte Daten für ihre Arbeit nutzen - zur Fördermittelakquise, zur Berichterstattung, zur Wirkungsmessung, zur Verbesserung ihrer Prozesse oder zum organisationellen Lernen? Mit welchen technischen Ansätzen können CiviCRM-Daten ausgewertet, analysiert und visualisiert werden?
Diese Fragen zu erkunden, war das Ziel eines internen Datenvorhabens, welches ein Team des Civic Data Labs im Sommer 2025 durchgeführt hat. Ausgehend von Gesprächen und schriftlichen Austauschen mit zivilgesellschaftlichen Akteur*innen zu ihrer CiviCRM-Nutzung recherchierten wir Tools und führten verschiedene technische Experimente durch, in denen wir Testdaten einer eigens eingerichteten CiviCRM-Instanz analysierten und visualisierten.
Dieses Lernmaterial dokumentiert die Ergebnisse dieses Datenvorhabens. Es richtet sich vor allem an Personen, die CiviCRM bereits nutzen und ihre CiviCRM Daten analysieren (wollen). Aber auch Personen, die überlegen, CiviCRM in ihrer Organisation einzuführen, oder die an Open Source Software oder gemeinwohlorientierter Datennutzung interessiert sind, sind herzlich willkommen, hier duchzustöbern.
Wie sollte dieses Lernmaterial gelesen werden?
Aufbau
Hauptteil dieser Ressource ist die Erklärung von Ansätzen zur Analyse und Visualisierung von Daten aus CiviCRM mithilfe von Toolkombinationen und anhand von konkreten Beispielen in Kapitel 2️⃣. Dabei wird auf detaillierte Beschreibungen und Erklärungen zu Tools verwiesen, die sich im Kapitel 3️⃣ befinden.
Mit Tools meinen wir technische Mittel unterschiedlicher Art: von Komponenten innerhalb von CiviCRM, über externe Anwendungen bis hin zu Programmiersprachen. Gemeinsam ist diesen Tools, dass sie eine Rolle bei der Analyse oder Visualisierung, bzw. der Herstellung der Möglichkeit zu letzterem spielen. Für die Definition dieser Rollen nutzen wir das Konzept des Datenlebenszyklus, das wir im Kapitel 1️⃣ vorstellen.
In Kapitel 4️⃣ ziehen wir ein Fazit zu unseren Experimenten.
Hinweise zur Bedienung
Zur Navigation kann die Seitenleiste und/oder die Pfeile am Ende der Unterseiten verwendet werden. Mit der 🔍 Suchfunktion kann die Seite nach Begriffen durchsucht werden.
Symbolerklärungen
In diesen Boxen erscheinen Tipps oder Informationen, die für das Verständnis des Beschriebenen direkt relevant sind.
Hier zitieren wir etwas und nennen die Quelle in den Fußnoten.1
Lebenszyklus von CiviCRM-Daten
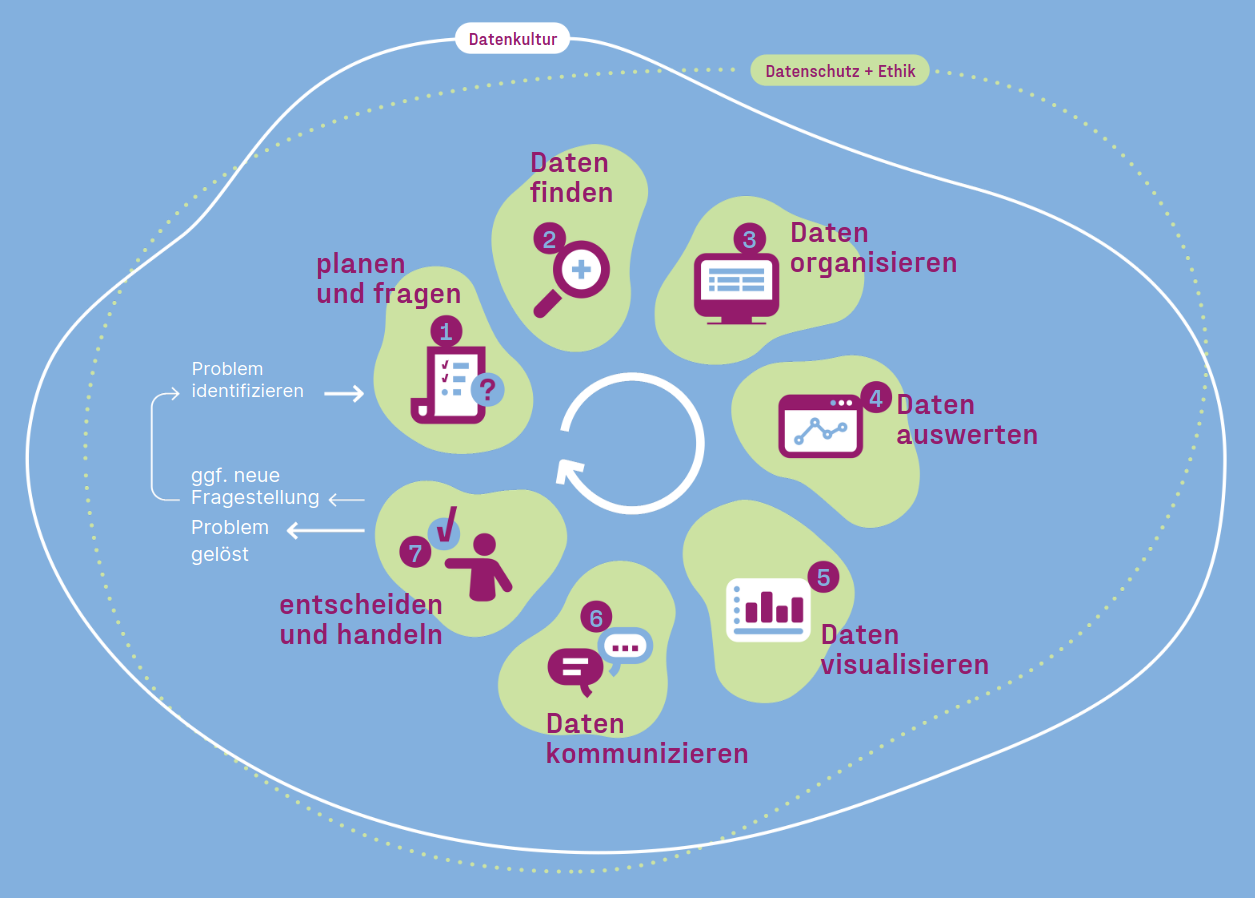
Der Datenlebenszyklus, visualisiert in der obigen Grafik, gibt einen Überblick über den Ablauf einer Datenanalyse - von der Planung bis hin zur Umsetzung. Wir werden dieses Konzept hier nicht genauer erklären und verweisen bei Bedarf und Interesse auf die entsprechende Informationsseite der Website des CDL.
Wir verwenden den Datenlebenszyklus hier, um Tools einzuordnen und fokussieren uns dabei auf die folgenden Aspekte:
Planen und fragen 🗺️
Welche Fragen will ich mithilfe von Daten beantworten? Welche Daten brauche ich?
Bei unserem Projekt gingen wir größenteils davon aus, dass interessierte Organisation schon Daten haben und auch wissen, welche Fragen sie an die Daten stellen wollen. Allerdings können manche Fragestellungen nur beantwortet werden, wenn man die in CiviCRM erfassten Daten um eigene Felder erweitert.
🗺️ Erweiterung von CiviCRM-Daten
Daten organisieren 🧹
Wo und wie werden Daten gespeichert? Wie werden sie verwaltet und wie werden sie bereinigt? Wie werden Datenflüsse zwischen Tools ermöglicht?
→ Daten in CiviCRM liegen in einer SQL-Datenbank bereits organisiert vor, was als Ort zur Speicherung, Organisation und Verwaltung von Daten häufig ausreicht. Wenn wir allerdings auf externe Tools zur Analyse und/oder Visualisierung zurückgreifen wollen, werden Ansätze und Methoden aus dem Bereich des Data Engineering und Data Modeling relevant, z.B. die Verwendung der CiviCRM API, einer Managed Datenbank oder die Integration von mehreren Tools mithilfe von Workflow Automation Tools.
🧹 CiviCRM Datenbank 🧹 Managed Datenbank 🧹 CiviCRM-API 🧹 Workflow Automation Tools 🧹 MS Power Query 🧹 Google Apps Script 🧹 Python
Daten auswerten 🔢
Wie werden Daten analysiert? Wie werden Ergebnisse analysiert?
→ CiviCRM Daten können unterschiedlich ausgewertet und analysiert werden: Von einfachen deskriptiven Analysen über tiefergehende Analysen hin zu komplexen Machine-Learning-Modellen zur Vorhersage von Spenden. Wir haben uns in unserer Arbeit überwiegend auf einfache Auswertungen fokussiert, da diese am übertragbarsten sind.
🔢 CiviCRM SearchKit 🔢 Excel, Google Sheets & Co. 🔢 Metabase & andere BI Tools 🔢 Python & R 🔢 CiviCRM Reports/Berichte
Daten visualisieren 📊
Wie werden Daten visuell ansprechend und passend für die Zielgruppe aufbereitet?
→ Viele Organisationen möchten ihre CiviCRM-Daten nicht nur auswerten, sondern auch in Datenvisualisierungen oder Dashboards aufbereiten.
📊 CiviCRM ChartKit 📊 Excel, Google Sheets & Co. 📊 Metabase & andere BI Tools 📊 Python & R 📊 Civisualize
Daten kommunizieren 💬
Wie werden Ergebnisse zielgruppengerecht kommuniziert und geteilt?
→ Auswertungen von CiviCRM-Daten können unterschiedliche Zielgruppen haben: man selbst, die eigene Organisation bzw. das eigene Team, die breite Öffentlichkeit, existierende Fördermittelgeber oder potenzielle Sponsor*innen. Je nach Zielgruppe(n) ergeben sich unterschiedliche Anforderungen an die Tiefe und Komplexität der Analyse, an das Design der Visualisierungen, an die Kommunikationswege.
Das Kommunizieren von Daten und Ergebnissen von Datenauswertungen ist eine Kunst bzw. ein Handwerk an sich1. Wir beschränken uns hier nur darauf, inwiefern Analyse- und Visualisierungs-Tools die Möglichkeiten bieten, Ergebnisse zu teilen, und inwiefern sie Ansprüche an Design und Professionalität erfüllen. Deshalb listen wir hier nicht separat “Datenkommunikationstools”.
Datenschutz
→ Da in CiviCRM fast immer personenbezogene Daten gespeichert werden, bildet Datenschutz einen wichtigen Rahmen für die Auswertung von CiviCRM-Daten. Dies ist vor allem relevant, wenn Daten außerhalb von CiviCRM weiterverarbeitet werden. Wir haben bei unserer Arbeit darauf geachtet, Tools zu priorisieren, die Datensouveränität ermöglichen.
Trotzdem haben wir auch Software von außereuropäischen Anbietern in unsere Recherche miteinbezogen. Wenn ihr diese Tools nutzen möchtet, empfehlen wir euch, Daten in CiviCRM oder europäischen Umgebungen so weit zu aggregieren, dass kein Rückschluss mehr auf Individuen möglich ist.
-
Das E-Learning Datenvisualisierung und Storytelling des Civic Data Labs gibt einen guten Einstieg ins Thema. ↩
Ansätze: Toolkombinationen
Um Daten in CiviCRM zu analysieren anzugehen, lassen sich fast immer mehrerer Lösungen finden. Es gibt kein „richtig“ oder „falsch“ – entscheidend ist, welche Tools und Methoden für euch am besten funktionieren.
Grundsätzlich könnt ihr unterscheiden, welche Schritte des Datenlebenszyklus ihr in CiviCRM und/oder extern abbildet:
- Alle Schritte in CiviCRM umsetzen (von Datenorganisation bis zur Datenvisualisierung).
- Daten organisieren und auswerten mithilfe von CiviCRM, Visualisierung und Kommunikation mit externen Tools.
- Nur Datenorganisation in CiviCRM, Auswertung, Visualisierung und Kommunikation mit externen Tools.
- Daten extern organisieren (z. B. in einer zusätzlichen Datenbank oder einem ETL-Tool), Auswertung und Visualisierung ebenfalls extern.
Generell gilt: CiviCRM ist primär ein CRM, kein Datenanalyse- oder Visualisierungstool. Je höher eure Anforderungen an die Auswertung sind, desto eher solltet ihr externe Tools hinzuziehen.
Darüber hinaus hängt die Wahl des Ansatzes von euren Ressourcen, Zielen und Anforderungen ab:
- Finanzielle Ressourcen eurer Organisation
- Bestehende technische Infrastruktur
- Vorhandene Fähigkeiten sowie Bereitschaft und Zeit, Neues zu erlernen
- Zielgruppe der Auswertung: interne Nutzung oder externe Stakeholder?
- Anforderungen an die Auswertungsergebnisse: Format, Design etc.
- Flexibilität: Soll explorativ gearbeitet oder nur eine festgelegte Auswertung durchgeführt werden?
Wir beschreiben Vor- und Nachteile der Tools und Ansätze, um euch bei der Entscheidung zu unterstützen – damit ihr eure CiviCRM-Daten bestmöglich auswerten könnt.
Aufbau dieses Kapitels
Bei der Sortierung der nachfolgenden Unterseiten haben wir die Ansätze nach Komplexität im Sinne von Menge an benötigten technischen Kenntnissen und Komponenten geordnet.
- Der am wenigsten komplexe Ansatz ist die ausschließliche Verwendung von CiviCRM-eigenen Tools wie SearchKit und ChartKit zur Analyse & Visualisierung.
- Wenn ihr externe Tools wie z.B. Metabase benötigt, ist deren Anschluss am einfachsten mit einer direkten Verbindung mit der CiviCRM-eigenen Datenbank möglich.
- Wenn eine direkte Anbindung an die CiviCRM-Datnbank nicht möglich ist (z.B. aus Sicherheitsgründen), könnt ihr selbst die API verwenden, um CiviCRM-Daten in anderen Tools zu analysieren, z.B. mithilfe von Excel oder Google Sheets
- Der Kategorie von Ansätzen, die am meisten der in der Disziplin des Data Engineering verbreiteten ETL-Prozessen (Extract, Transform & Load) gleichen, haben wir dabei mit einer eigenen Erklärungsseite ausgestattet.
SearchKit & ChartKit
Wir verwenden die Tools, die bereits in CiviCRM vorhanden sind, um Daten zu analysieren und zu visualisieren.
🧹 daten-organisieren: CiviCRM Datenbank
🔢 daten-auswerten: SearchKit
📊 daten-visualisieren: ChartKit
Voraussetzungen
Anleitung
Setup
kein weiterer Setup nötig. :)
Datenauswertung
- Legt eine neue Suche in SearchKit an oder bearbeitet eine existierende Suche. Im Visualisierungsschritt habt ihr Zugriff auf die Spalten der Ergebnisse der SearchKit-Suche. Überlegt euch daher schon jetzt, welche Datenpunkte eure Visualisierung benötigt.
Visualisierung
- im SearchKit Editor links Hinzufügen -> Diagramm
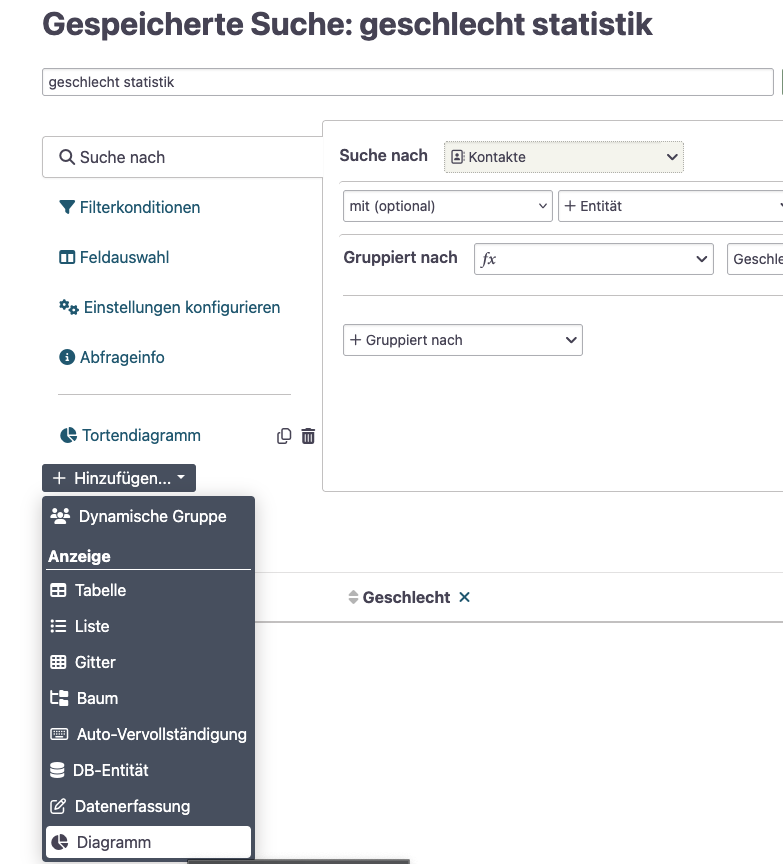
- im ChartKit Editor können verschiedene Visualisierungstypen über ein grafisches User Interface konfiguriert werden. Verwendet werden können die Spalten der Ergebnisse der SearchKit Suche.
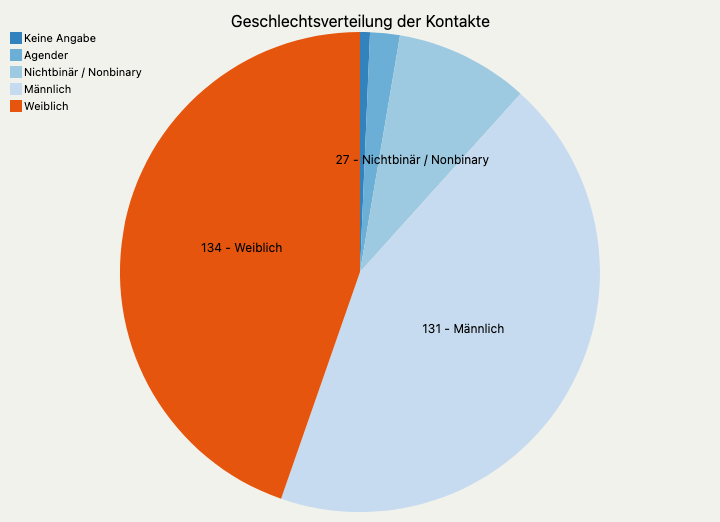
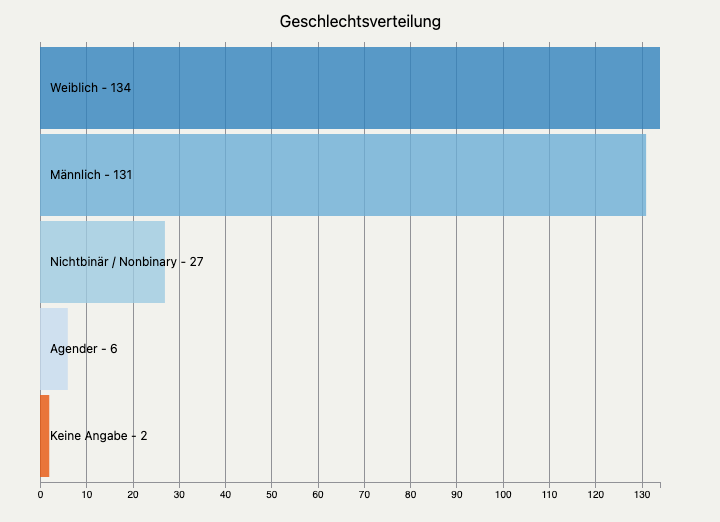
Use Case: Darstellung der Geschlechtsverteilung
Einfache grafische Darstellungen sind hilfreich, um z.B. die Zusammensetzung der eigenen Zielgruppe zu verstehen. Hier machen wir eine einfache Auswertung der Geschlechtsverteilung unserer Kontakte.
Die Tabelle, die aus unserer SearchKit-Suche herauskommt, sieht wie folgt aus:
| Geschlecht | Anzahl CiviCRM-ID |
|---|---|
| Weiblich | 134 |
| Männlich | 131 |
| Nichtbinär / Nonbinary | 27 |
| Agender | 6 |
| Keine Angabe | 2 |
Ihr könnt die Suche bei euch importieren über SearchKit -> Import. Den Code findet ihr hier. Voraussetzung ist, dass die Geschlechtsvariable bei euch gleich benannt sind.
Um die Daten darzustellen, können wir wie oben beschrieben ChartKit nutzen. Hier haben wir zwei Visualisierungen erstellt, ein Torten- und ein Balkendiagramm.
Ihr könnt eure Visualisierungen in CiviCRM im Browser ansehen. Personen, die Zugriff auf die CiviCRM-Suche haben, haben auch Zugriff auf die dazugehörigen ChartKit-Visualisierungen. Es ist nicht möglich, diesen Link mit Externen ohne CiviCRM-Account zu teilen.
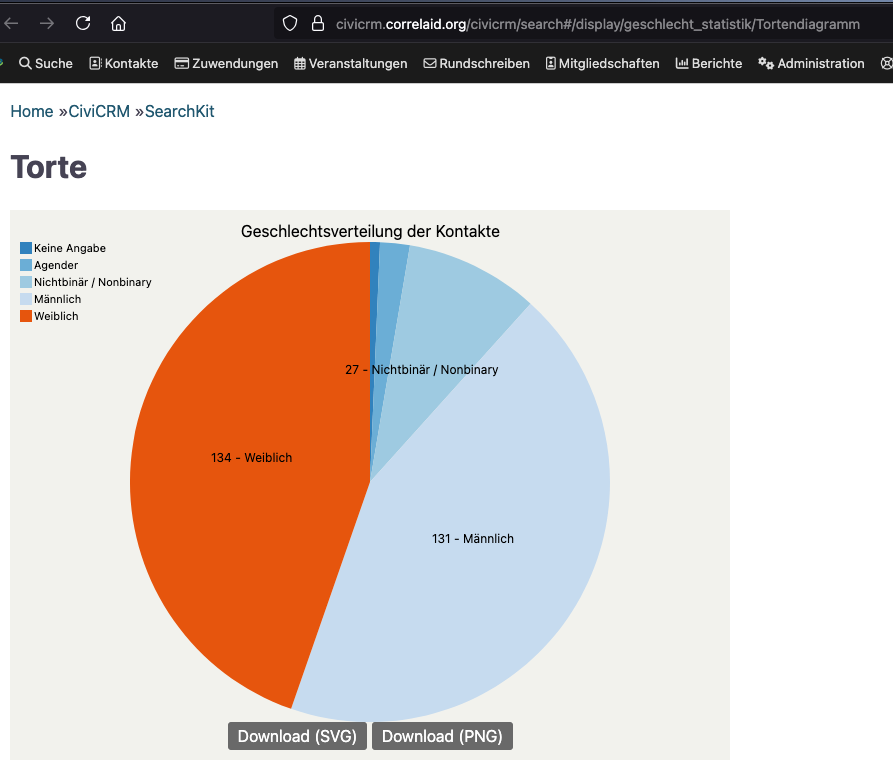
Mithilfe der eingebetteten Download-Links könnt ihr sie als PNG- oder SVG-Datei herunterladen.
Fazit
SearchKit und ChartKit ermöglichen in CiviCRM einen unkomplizierten, voraussetzungsniedrigen Setup für Datenanalyse und Visualisierung. ChartKit ist direkt in SearchKit integriert, sodass Visualisierungen direkt bei den dazugehörigen Suchen gespeichert werden. Das bedeutet allerdings, dass ihr eure Visualisierungen nicht anders anordnen oder sortieren könnt, z.B. in einem Dashboard. Auch könnt ihr eure Visualisierungen nicht direkt über Links mit externen Stakeholdern teilen oder zugänglich machen. Dafür ist die Exportfunktion gut zugänglich.
Die Kombination von Search- und ChartKit ist gut geeignet, wenn ihr ausgewählte Visualisierungen direkt in CiviCRM verfügbar haben wollt und diese nur selten und anlassbezogen exportieren müsst. Wenn ihr Darstellungen live mit Externen teilen oder ein Dashboard bauen wollt oder generell höhere Anforderungen an die Gestaltung habt, seid ihr (noch) auf externe Tools angewiesen.
SearchKit & Excel / Google Sheets
Wir laden SearchKit Suchergebnisse über die API in Excel oder Google Sheets. Die Datenvisualisierung und weitere Auswertung machen wir dort.
🧹 daten-organisieren: CiviCRM Datenbank; Power Query bzw. Google Apps Script zur Ansprache der CiviCRM API
🔢 daten-auswerten: SearchKit
📊 daten-visualisieren: Excel bzw. Google Sheets
SearchKit, Excel und Power Query
Voraussetzungen
- CiviCRM API Schlüssel, um auf die folgenden Endpunkte der CiviCRM API eurer Instanz zuzugreifen:
ajax/api4/SavedSearch/getajax/api4/SearchDisplay/download
- Lizenz für Microsoft Excel Desktop Version1, optional für Excel für das Web
Bei diesem Ansatz hinterlegt ihr euren API-Schlüssel in einer Excel-Datei. Alle Personen, die diese Datei öffnen, können somit auf euren API-Schlüssel und somit auf die Daten zugreifen, auf die ihr in CiviCRM Zugriff habt. Seid euch der Risiken bewusst und geht verantwortungsvoll mit entstandenen Dateien um.
Anleitung
A. Setup
-
Ladet die
test-excel.xlsxDatei aus dem GitHub Repository herunter. Dazu oben rechts auf die drei Punkte und dann auf "Download" bzw. "Herunterladen" klicken. -
Öffnet die Datei in der Desktop Version von Microsoft Excel.
-
Aktiviert die externen Datenverbindungen, indem ihr auf "Inhalt aktivieren" klickt.

-
Öffnet den Power Query Editor über den Ribbon Daten -> Daten abfragen (Power Query) -> Power Query-Editor starten.
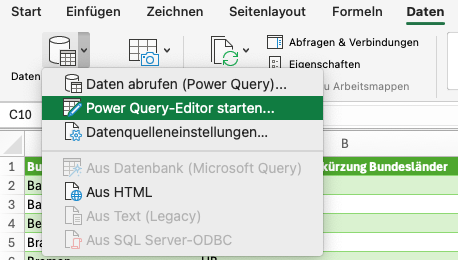
- In der Seitenleiste links wählt den Eintrag
CiviToken. Gebt euren API Schlüssel für die CiviCRM API ein. Klicke auf "Übernehmen".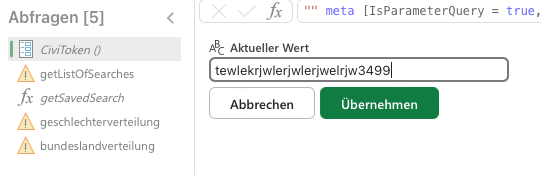
B. Eigene SearchKit-Suchen herunterladen
Im Power Query Editor ist die Funktion getSavedSearch (dt. "bekomme gespeicherte Suche") hinterlegt. Mit dieser Funktion könnt ihr eigene SearchKit Suchen abfragen.
-
In der linken Seitenleiste -> fx
getSavedSearch -
in das Feld "SearchName" den Namen eurer SearchKit Suche eingeben. Wichtig: Leerzeichen müsst ihr mit Unterstrichen ersetzen. z.B. wird "geschlecht statistik" zu "geschlecht_statistik" oder "Zuwendungen nach Zahlungsmethode" zu "Zuwendungen_nach_Zahlungsmethode". auf "Aufrufen" klicken.
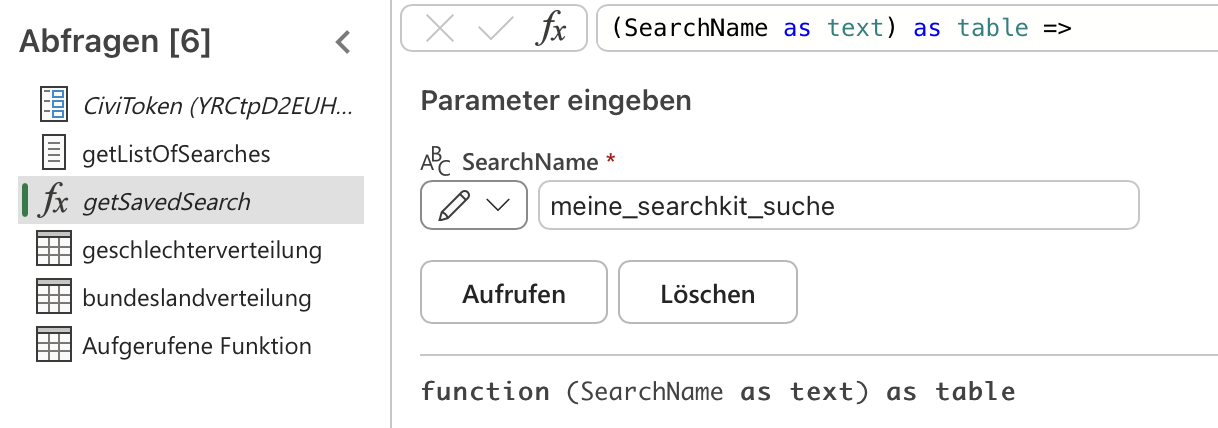
-
dies legt einen neuen Query in der Seitenleiste an und führt ihn direkt aus. Ihr könnt dem Query mit Rechtsklick einen aussagekräftigeren Namen geben.
-
Wenn ihr ganz normal auf den Query in der Seitenleiste klickt, solltet ihr das Ergebnis eurer SearchKit Suche als Tabelle sehen.
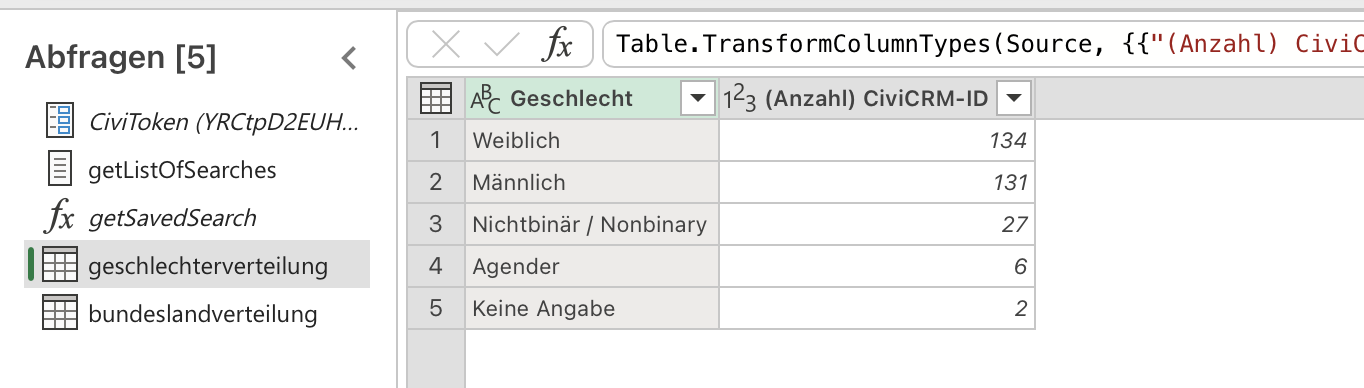
-
Sehr ihr anstatt dessen eine Warnung oder einen Fehler, ist etwas schief gelaufen. Überprüft, ob ihr die richtigen Zugriffsrechte habt und ob ihr den API Schlüssel bei Setup richtig hinterlegt habt.
-
Um in Excel gut weiterarbeiten zu können, müsst ihr noch sicherstellen, dass die Daten den richtigen Typ haben. Das ist v.a. wichtig für Zahlenwerte wie Anzahl, Mittelwert, usw. Hierzu in der Vorschautabelle im Power Query Editor Rechtsklick auf den Spaltennamen -> Änderungstyp. Dann den gewünschten Datentyp auswählen.
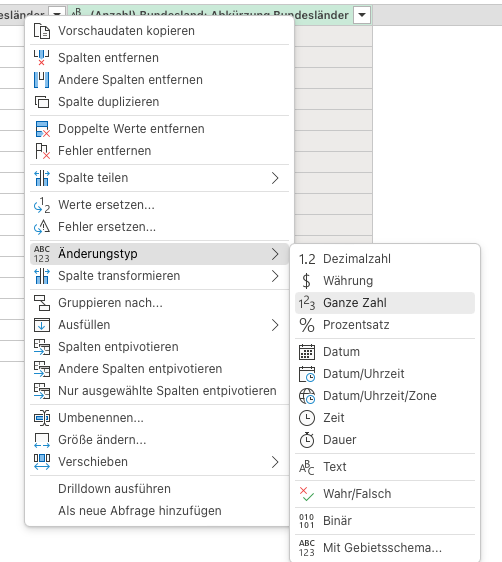
- Schließt den Power Query Editor mit dem Button Schließen und Laden. Dies legt ein neues Tabellenblatt für die neuen Queries an und fügt die Ergebnistabellen dort ein.
- Ihr könnt jetzt die Tabelle markieren mit den Daten weiterarbeiten: z.B. ein Diagramm (Einfügen -> Diagramm auswählen) oder eine Pivot-Tabelle (Einfügen -> PivotTable) einfügen.
Tipp: auf Windows könnt ihr noch genauer kontrollieren, wie und wo ihr eure Power Queries verwenden wollt. Auf Youtube gibt es viele Videos zu Power Query, die mit der Windows Version arbeiten und euch zeigen, was ihr noch so machen könnt.
C. Power Queries aktualisieren und bearbeiten
Über Ribbon Daten -> Alle Aktualisieren könnt ihr eure Power-Query-Abfragen aktualisieren. Verbundene Diagramme, Pivot-Tabellen und sonstige Auswertungen aktualisieren sich automatisch.
Falls ihr die Funktion bearbeiten möchtet, könnt ihr dies über Rechtsklick auf getSavedSearch -> Erweiterter Editor tun. Den Code für die Funktion sowie einen Power Query, der euch eine Liste aller SearchKit Suchen zurückgibt, haben wir auch im GitHub Repository hinterlegt.
Power Query wird in Excel für das Web nur eingeschränkt unterstützt. Es gibt keinen Power Query Editor, aber bestehende Queries funktionieren und es gibt den "Alle aktualisieren" Button. Verwendet ihr Excel in der Cloud, kann ein*e Kolleg*in die Queries anlegen und dann die Excel-Datei in die Cloud laden.
Fazit
Die Verwendung von Microsoft Excel und PowerQuery ist vor allem sinnvoll, wenn ihr ...
- a) ... sowieso schon Daten in Excel verwaltet und ihr diese mit Daten aus eurem CiviCRM kombinieren wollt
- b) ... eine unkomplizierte, interne Lösung sucht, um einfache Grafiken und "Dashboards" zu erstellen
Da es sich bei Microsoft um einen US-amerikanischen "Big-Tech" Anbieter handelt, solltet ihr auf Datenschutz und auch -sicherheit achten, vorzugsweise nur aggregierte Daten importieren und generell überlegen, welche Art von Daten ihr "in die Hände von Google" geben wollt, selbst wenn sie nicht mehr unter die DSGVO fallen.
SearchKit, Google Sheets und Google Apps Script
Voraussetzungen
- CiviCRM API Schlüssel, um auf die folgenden Endpunkte der CiviCRM API eurer Instanz zuzugreifen:
ajax/api4/SavedSearch/getajax/api4/SearchDisplay/download
- Google Konto2
Bei diesem Ansatz hinterlegt ihr euren API-Schlüssel in einem Google Apps Script. Alle Personen, die Mitarbeiter-Zugriff (en: Editor) auf das Google Sheet haben, können auf den Apps Script Editor und somit auf euren API-Schlüssel und alle Daten zugreifen, auf die ihr in CiviCRM Zugriff habt. Seid euch der Risiken bewusst und geht verantwortungsvoll mit Zugriffsrechten um.
Anleitung
A. Setup
Schneller Setup
- Erstellt eine Kopie dieses Google Sheets: Datei -> Kopie erstellen.
- Ihr bekommt eine Warnung, dass eine Apps Script-Datei ebenfalls kopiert wird. Ihr könnt den Code erst überprüfen, bevor ihr eine Kopie erstellt.
- Öffnet das erstellte Google Sheet und öffnet die Google Apps Script Konsole über Erweiterungen -> Apps Script. Ein neues Fenster öffnet sich mit der Datei
runAllSearches.gsgeöffnet.
Der Code ist auf zwei .gs-Dateien3 aufgeteilt:
runAllSearches.gs: hier gebt ihr euren API-Schlüssel ein und verwendet die FunktionfetchSavedSearch, um Ergebnisse einer oder mehrerer SearchKit-Suche(n) mithilfe CiviCRM-API in das Google Sheet zu importieren.fetchSavedSearch.gs: enthält die FunktionfetchSavedSearch
Den Code findet ihr auch im GitHub Repository.
Manueller Setup
- Erstellt ein leeres Google Sheet und gebt ihm einen sinnvollen Namen (z.B. "CiviCRM API Test")
- Öffnet Google Apps Script (Erweiterungen -> Apps Script). Es öffnet sich ein Editor.
- Benennt die Datei
Code.gsum inrunAllSearches(drei Punkte rechts neben Namen -> Umbenennen) und drückt Enter. - Löscht den Beispielcode und kopiert den Code der Datei
runAllSearches.jsin das Editorfenster. Speichert mithilfe vonSTRG/CMD+Soder dem Diskettensymbol. - Erstellt eine neue Script-Datei im Apps Script Editor: + Zeichen bei Datei -> Script
- Löscht den Beispielcode und kopiert den Code der Datei
fetchSavedSearch.jsin das Editorfenster. Speichert mithilfe vonSTRG/CMD+Soder dem Diskettensymbol.
B. Apps Script ausführen & automatisieren
Manuelle Ausführung
Um den Code laufen zu lassen, drückt ihr auf den Button "Ausführen" (en: "Run") (nicht: "Bereitstellen"!), wenn ihr runAllSearches.gs geöffnet habt. Wenn ihr zum ersten Mal den Code ausführt, werdet ihr dazu aufgefordert, der App Berechtigungen zu geben (mehr dazu im aufklappbaren Infokasten).
Im Ausführungsprotokoll (en: Execution Log) könnt ihr nachvollziehen, ob die Ausführung funktioniert.
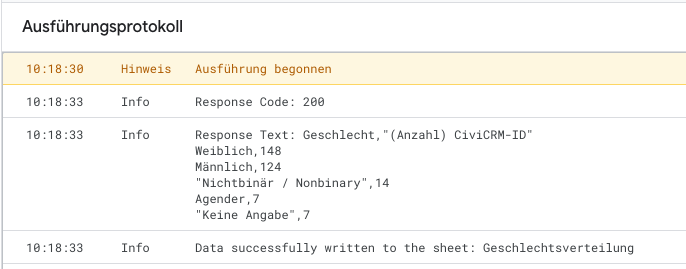
Die Sache mit den Berechtigungen
Die Sache mit den Berechtigungen
Wenn ihr zum ersten Mal den Code ausführt, werdet ihr dazu aufgefordert, der App Berechtigungen zu geben. Dies müsst ihr tun, damit das Skript auf die CiviCRM-API zugreifen kann und die Daten in das Google Sheet schreiben kann. Wenn ihr Google Chrome verwendet, folgen weitere Warnungen, da es sich nicht um eine "verifizierte App" handelt.
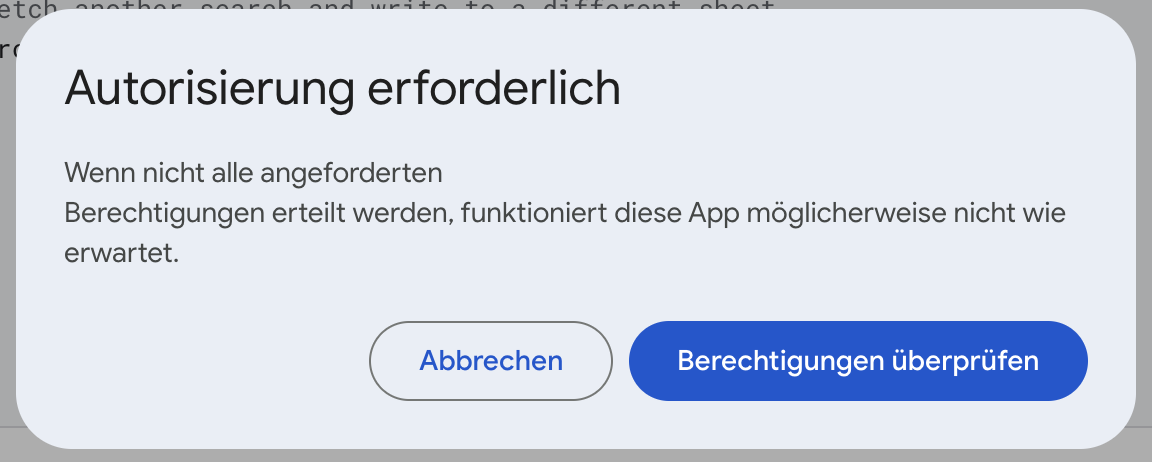
Die Berechtigungen gelten nur für eure eigene Kopie der App. Diese habt ihr erstellt, ...
- ... indem ihr das von uns bereitgestellte Google Sheet mit dem dazugehörigen Apps Script Code kopiert habt ("schneller Setup"). Wir haben auf eure Kopie des Google Sheets keinen Zugriff.
- ... indem ihr eine eigenes Google Sheet plus eigenem Apps Script Code erstellt habt ("manueller Setup"). Wir haben auf euer Google Sheet und auch den Code keinen Zugriff.
Trotzdem solltet ihr Code, den ihr von anderen übernehmt, immer sorgfältig prüfen. Hier können euch LLMs oder ein Blick durch Expert*innen weiterhelfen.
Automatisierte Ausführung
Damit ihr nicht jedes Mal auf "Ausführen" klicken müsst, könnt ihr die Ausführung von runAllSearches.gs auch mithilfe von sogenannten Triggern automatisieren. Trigger lösen die Ausführung des Skripts aus. Es gibt verschiedene Trigger (z.B. beim Öffnen des Google Sheets etc.), eine Übersicht findet ihr hier.
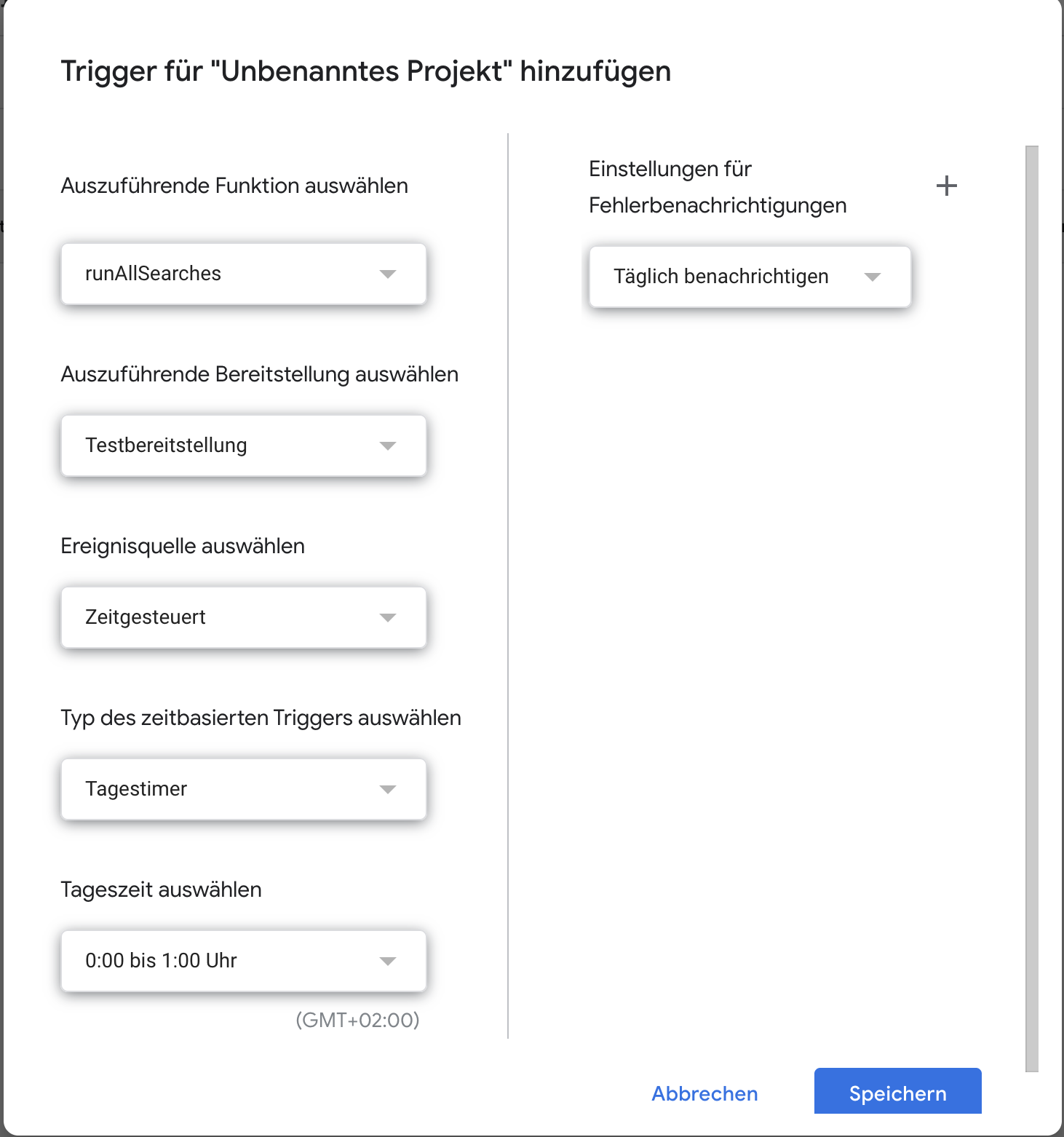
Die genaue Wahl des Triggers hängt von eurer Anwendung ab. Wir empfehlen:
- Zeitgesteuert: Aktualisiert die Daten und damit verknüpften Visualisierungen regelmäßig. Den genauen Rhythmus (stündlich/täglich/wöchentlich) legt ihr fest. Eine populäre Wahl ist einmal pro Tag mit Ausführung in der Nacht (siehe Screenshot).
- beim Öffnen des Google Sheets: Garantiert, dass sich eure Daten und damit verknüpfte Visualisierungen bei jedem Öffnen des Sheets aktualisieren.
Die Einrichtung eines Triggers ist intuitiv über eine grafische Benutzeroberfläche im Google Apps Script Editor möglich. Eine kurze Anleitung findet ihr hier.
C. Eure eigenen Suchen abrufen
Um eure eigenen Suchen abzurufen, müsst ihr den Code im Google Apps Script Editor anpassen.
In der Datei runAllSearches.gs:
- Fügt in Zeile 2 euren API-Schlüssel zwischen den "" ein.
- Fügt in Zeile 10 den Namen eurer SearchKit Suche und den Namen des Tabellenblatts in den Funktionsaufruf von
fetchSavedSearchjeweils zwischen den "" ein. Das Tabellenblatt muss noch nicht existieren, die Funktion erstellt es dann automatisch. - Optional: Wiederholt Schritt 1+2 in Zeile 14, wenn ihr zusätzlich Ergebnisse einer anderen Suche in ein weiteres Tabellenblatt importieren wollt. Falls nicht, löscht den Code in Zeile 14.
- Optional: Wenn ihr noch mehr Suchen importieren wollt, könnt ihr den Code aus Zeile 10 so oft kopieren und anpassen (siehe Schritte 1+2), wie ihr wollt.
function runAllSearches() {
var apiKey = "fügt euren API-SCHLÜSSEL hier ein"; // Replace with your actual API key within the "", e.g. "b2391932kss"
// Dokumentation der fetchSavedSearch Funktion
// fetchSavedSearch(searchName, sheetName, apiKey);
// @param {string} searchName - The name of the saved search in CiviCRM.
// @param {string} sheetName - The name of the sheet in the Google Spreadsheet where data should be written. Does not need to exist when executed
// @param {string} apiKey - Your CiviCRM API key.
fetchSavedSearch("fügt den Namen eurer SearchKit Suche hier ein", "fügt den Namen des Google Sheet Blattes hier ein", apiKey);
//Beispiel: fetchSavedSearch("geschlecht_statistik", "Geschlechtsverteilung", apiKey);
// ihr könnt noch mehr Suchen in anderen Blättern abrufen
fetchSavedSearch("fügt den Namen eurer SearchKit Suche hier ein", "fügt den Namen des Google Sheet Blattes hier ein", apiKey);
//Beispiel: fetchSavedSearch("Bundesland", "Bundeslandverteilung", apiKey);
}
Folgt der Anleitung in B. Apps Script ausführen, um euren angepassten Code auszuführen.
D. Visualisierung
Sobald die Daten in Google Sheets importiert sind, könnt ihr wie gewohnt die Visualisierungstools von Google Sheets verwenden, um Balken-, Tortendiagramme usw. zu erstellen. Auf YouTube und mit der Suchmaschine eurer Wahl findet ihr zahlreiche Ressourcen.
Die Visualisierungen könnt ihr im jeweiligen Tabellenblatt hinzufügen oder in einem eigenen "Dashboard"-Sheet arrangieren (z.B. hier).
Die interaktiven Datenvisualisierungen lassen sich einzeln veröffentlichen und in eine Website einbetten. Hier der Donut-Chart zur Geschlechtsverteilung, den ihr auch im Sheet "Dashboard" unseres Google Sheets findet:
Google Sheets als Datenquelle für andere Visualisierungstools
Google Sheets als Datenquelle für andere Visualisierungstools
Einige Tools zur Datenvisualisierung können Google Sheets als Datenquelle verwenden (z.B. DataWrapper oder Canva). Anstelle die Visualisierungen direkt in Google Sheets zu erstellen, könnt ihr Google Sheets auch nur als "automatisiert aktualisierten Zwischenspeicher" verwenden. Achtet hierbei auf Datensicherheit - manchmal müsst ihr euer Google Sheet (teilweise) publizieren.
Fazit
Die Verwendung von Google Sheets und Google Apps Script ist vor allem sinnvoll, wenn ihr ...
- a) ... sowieso schon Daten in Google Sheets verwaltet und ihr diese mit Daten aus eurem CiviCRM kombinieren wollt
- b) ... eine unkomplizierte, interne Lösung sucht, um einfache Grafiken und "Dashboards" zu erstellen
- c) ... einen "Zwischenspeicher" für andere Anwendungen benötigt, die Google Sheets als Datenquelle verwenden können
Da es sich bei Google um einen US-amerikanischen "Big-Tech" Anbieter handelt, solltet ihr auf Datenschutz und auch -sicherheit achten, vorzugsweise nur aggregierte Daten importieren und generell überlegen, welche Art von Daten ihr "in die Hände von Google" geben wollt, selbst wenn sie nicht mehr unter die DSGVO fallen.
-
Für die Einrichtung und Konfiguration ist die Desktop Version von Excel notwendig. Das Abrufen der Daten funktioniert dann auch unter Excel für das Web, wenn man die Datei hochgeladen hat. Der Ansatz wurde getestet unter Microsoft Excel for Mac, Version 16.100.3 unter der Lizenz Microsoft 365. ↩
-
Wir haben den Ansatz mit einem Google Account getestet aus unserem Google Workspace for Nonprofits. Theoretisch sollte es aber auch mit einem kostenlosen, privaten Google Account funktionieren. ↩
-
gssteht für Google Apps Script. Technisch gesehen ist Google Apps Script eine Version von JavaScript. ↩
CiviCRM Datenbank & Metabase
Wir verbinden das Business Intelligence Tool Metabase mit der CiviCRM Datenbank und verwenden es, um Daten auszuwerten und zu visualisieren.
🧹 daten-organisieren: CiviCRM Datenbank und (partiell) in Metabase, direkte Anbindung der CiviCRM Datenbank an Metabase
🔢 daten-auswerten: Metabase
📊 daten-visualisieren: Metabase
Voraussetzungen
- Direkter Zugriff auf eure CiviCRM Datenbank
- Einen Account für eine Metabase Instanz mit Admin-Rechten
Anleitung
A. Setup
Fügt wie hier beschrieben eine Verbindung zu eurer Datenbank zu Metabase hinzu.
B. Daten analysieren und visualisieren
Sobald Metabase Zugriff auf eure CiviCRM-Datenbank habt, könnt ihr Fragen erstellen und diese in Dashboards visualisieren und darstellen. Mehr zur Analyse und Visualisierung in Metabase hier.
C. Daten organisieren
Die CiviCRM-Datenbank hat sehr viele Tabellen - verständlich bei so einer umfassenden Softwarelösung. Zum Beispiel sind in der Tabelle Kontakte nur numerische IDs für das Geschlecht vorhanden. Die Labels finden sich in einer eigenen Tabelle. Diese Tabellen bei jeder Frage zusammenzuführen, ist auf Dauer nervig und zeitraubend. Es lohnt es sich daher, ein bisschen Datenmodellierung in Metabase zu machen. Hierfür könnt ihr die Modell-Funktion verwenden. So könnt ihr z.B. ein Modell “Kontakte” anlegen, welches die Genderoptionen bereits an die Kontakte-Tabelle anfügt. Euer Modell könnt ihr dann in allen weiteren Fragen und verbundenen Analyse- und Visualisierungsschritten nutzen.
Use Case: Kontakt- und Spendendashboard
Als Teil des Datenvorhabens haben wir ein Dashboard erstellt, welches einen Überblick über die Kontakte und Spenden + Kampagnenbeiträge in unserer Testdatenbank gibt. Das Dashboard hat zwei Tabs:
- Kontakte: Deskriptive Statistiken zu unseren Fake-Kontakten
- Spenden: Deskriptive Statistiken zu Zuwendungen, spezifisch zu Spenden und Kampagnenbeiträgen.
Als kleiner Vorgeschmack hier die Visualisierung unserer fiktiven Spendenkampagne im Dezember 2024:
Vorteile
- Über die Datenbank erhaltet ihr Zugriff auf den gesamten Umfang eurer Daten und seid somit sehr flexibel in euren Auswertungen
- Tools wie BI-Tools funktionieren am besten mit einer direkten Verbindung mit der CiviCRM-Datenbank
Nachteile
- Datensicherheit: ein direkter Zugriff auf die Datenbank ist auch immer ein Datensicherheitsrisiko. Deshalb kann euer CiviCRM-Dienstleister (berechtigte) Bedenken haben, euch diesen Zugriff zu gewähren. Greift wenn möglich auf die API zurück.
- Komplexität: Die Daten liegen in der CiviCRM in zahlreichen Tabellen ab. Sich hier zurecht zu finden, erfordert eine Einarbeitung in SQL und einen gewissen Spürsinn: Die Entity-Relationship-Diagramme (ERDs) für CiviCRM sind zwar hier dokumentiert, aber trotzdem müsst ihr euch sicher zu einem gewissen Grad selbst durch die Daten "wühlen", v.a. wenn ihr Daten aus verschiedenen CiviCRM-Datentypen kombinieren wollt.
Fazit
Für die Verwendung von bestimmten externen Tools (v.a. BI-Tools) kann ein direkter Zugriff auf die CiviCRM-Datenbank sinnvoll sein. Aufgrund der Datensicherheitsrisiken solltet ihr sehr verantwortungsbewusst mit dieser Option umgehen und Rücksprache mit eurem CiviCRM-Dienstleister halten.
Falls ihr für externe Tools den Zugriff auf eine Datenbank benötigt, ist alternativ das Duplizieren eines Teils der CiviCRM Daten in eine Managed Datenbank über die API und Workflow-Tools eine Option. Siehe dafür das Kapitel zu ETL.
ETL: CiviCRM API, Automation, Managed DB & Metabase
flowchart TB
subgraph CiviCRM
API[API]
end
subgraph ETL[Automation Tool Knoten]
Extract[Daten extrahieren]
Transform[Daten transformieren]
Load[Daten in die DB laden]
Extract --> Transform --> Load
end
ExtDB[(Managed DB)]
Metabase[Metabase]
ETL -->|Modellierung in API-Explorer| API
ETL --> ExtDB
Metabase --> ExtDB
In diesem Unterkapitel werden Tool-Kombinationen vorgestellt, mit denen sich ETL-Prozesse (Extract, Transform & Load) umsetzen lassen. Über eine API extrahieren wir Daten aus CiviCRM, um sie dann zu verarbeiten und schließlich in eine externe Datenbank zu laden.
Die externe Datenbank dient als Data Warehouse. Die Prozesse werden ausgeführt von einem Workflow Automation Tool, das hier für Data Orchestration eingesetzt wird. Zusätzlich schließen wir Metabase an die externe Datenbank an, um die Daten visualisieren zu können.
Zum einen ist der Betrieb von CiviCRM abhängig von einer Datenbank (Anwendungsdatenbank). Wenn wir nun Anfragen auf dieser Datenbank laufen lassen, könnte das für Nutzer:innen zu längeren Wartezeiten oder gar Ausfällen führen. Zum anderen ist der Sinn von einem klassischen Data Warehouse Daten aus verschiedenen Quellen für Analyse modelliert und transformiert zu speichern, was bei der Anwendungsdatenbank nicht unbedingt der Fall sein muss. Außerdem haben Data Warehouses andere Betriebsanforderungen.
ETL & Relational Data Warehouse
ETL & Relational Data Warehouse
Die vorgestellten Ansätze sind eine reduzierte Form von ETL und unterscheiden sich in verschiedenen Hinsichten von üblichen Vorgehensweisen. Die wichtigsten Transformationsschritte die wir durchführen, werden über die API abgebildet. Oft wird dafür ein spezielles Tool wie dbt genutzt.
Unsere managed Datenbank, die selbst relational ist, nutzen wir als Relational Data Warehouse. Dies bedeutet, das wir die Daten in einer bestimmten strukturierten Form speichern und abfragen können. Alternativen dazu sind Warehouse-Architekturen wie Data Lakes, wo Daten in weniger strukturierter Form gespeichert werden.
Eine gute Erklärung dieser Begriffe findet ihr in diesem Video.
Dieser ETL-Ansatz wird anhand von zwei Use Cases veranschaulicht, bei denen jeweils eines der zwei ausgewählten Workflow Automation Tools verwendet wird. Zuerst erklären wir, wie man mit n8n durch das Duplizieren eines Datenausschnitts die Datengrundlage für die Visualisierung einfacher deskriptive Statistiken schaffen kann.
Danach wird der komplexere Use-Case der Visualisierung von Spender:innenwanderungen thematisiert. Nachdem notwendige Daten über einen API-Request aggregiert wurden, geschieht dies mithilfe von Kestra.
Basic ETL mit n8n - Einfache deskriptive Statistiken
Wir orchestrieren einen ETL-Prozess (Extract, Transform & Load) mit n8n um die Frage zu beantworten, wie sich Gender unter den in CiviCRM erfassten Kontakten verteilt und wollen dies mit einen Donut-Chart visualisieren.
🧹 daten-organisieren: CiviCRM API Explorer & Neon; CiviCRM API & n8n
🔢 daten-auswerten: Metabase
📊 daten-visualisieren: Metabase
Voraussetzungen
- Account bei Neon
- API-Token für eine CiviCRM-Instanz
- n8n-Instanz oder ein Abonnement des n8n SaaS
- Metabase-Instanz oder ein Abonnement des Metabase SaaS
Anleitung
Dieser Ansatz besteht aus vier Komponenten, die wir nacheinander vorbereiten.
A: Anlegen einer Tabelle in der Managed Datenbank (Neon)
Option 1: GUI
Erstelle eine neue Tabelle (wie hier beschrieben)
- Gebe der Tabelle den Namen
kontakte - Füge die Spalten
civicrm-idundgenderhinzu - Wähle für
civicrm-idden Datentypintegerund die contraintsNot null, sowieUniqueaus - Wähle für
genderden Datentypvarcharund den contraintsNot nullaus
Constraints
Constraints
Constraints sind Regeln, die die Datenintegrität und -konsistenz gewährleisten, indem sie festlegen, welche Daten wie in Tabellen gespeichert werden dürfen. Sie dienen als Datenvalidierungsprüfungen auf Ebene der Datenbank.
Option 2: SQL-Editor
Die Tabelle lässt sich im SQL-Editor von Neon durch das Ausführen des folgenden Codes erstellen:
CREATE TABLE "kontakte" (
"id" integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY (sequence name "kontakte_id_seq"),
"civicrm_id" integer NOT NULL UNIQUE,
"gender" varchar
);
Diesen und anderen SQL-Code findet ihr auch im Repository in dem Ordner supporting_code/sql.
B: Datenmodellierung im API-Explorer von CiviCRM
Navigiert zum API Explorer und wählt als Entität Contact, sowie als Aktion get aus. Unter select, wählt gender_id:label und id aus. Wichtig ist, dass ihr außerdem -1 bei limit setzt, um alle Daten zu erhalten. Bei diesem Use Case beschränkt sich die Datenmodellierung auf die Feldauswahl.
Tabellen in CiviCRM
Tabellen in CiviCRM
gender ist eine separate Tabelle, die alle auf dieser CiviCRM-Instanz auswählbaren Gender enthält. Kontakte haben ein Feld mit dem Namen gender_id, das die ID einer Reihe in der Gender-Tabelle enthält, die zum Beispiel als Spalte Label hat.
Nach diesen Schritten könnt ihr bereits den Request Body weiter unten unter REST kopieren. Dies sollte entsprechen:
params=%7B%22select%22%3A%5B%22gender_id%3Alabel%22%2C%22id%22%5D%7D
C: Anlegen des Flows in n8n
Erstellt einen neuen Workflow auf eurer n8n-Instanz. Am Ende sollte dieser so aussehen:
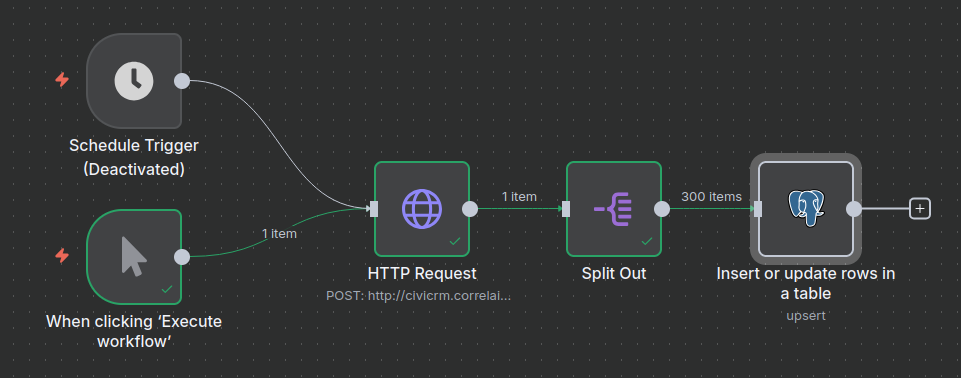
Den Flow als importierbare Datei findet ihr auch im Repository in dem Ordner supporting_code/n8n_flows
Als Trigger dient sowohl die manuelle Ausführung als auch eine Schedule (regelmäßig terminiertes Ausführen). Letzteres kann zum Beispiel einmal am Tag geschehen.
D: Knoten für die API-Anfrage anlegen
Der erste richtige Knoten enthält die API-Anfrage. Unten seht ihr, wie ihr ihn konfigurieren müsst.
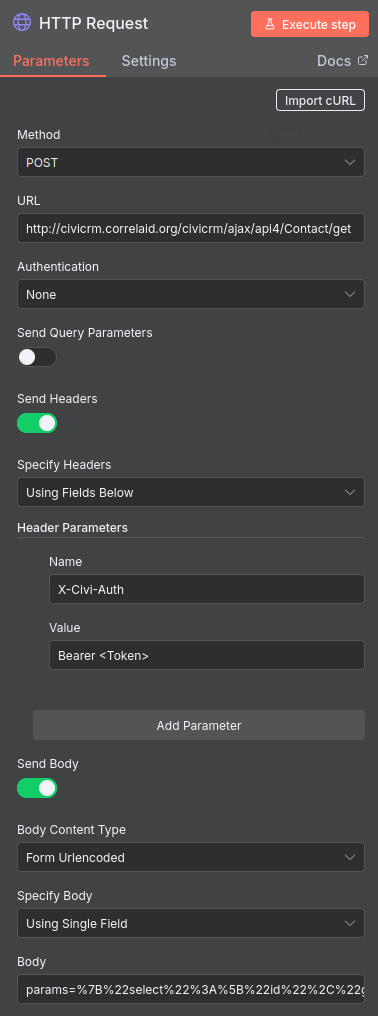
-
Fügt unter URL am Anfang die URL eurer Instanz ein. Im API Explorer unter dem Reiter REST ist dies auch als Variable
CRM_URLdefiniert. -
Fügt euer API-Token an der Stelle ein, wo im Screenshot <Token> steht.
-
Im Feld Body, das bei Setzen der oben angezeigten Optionen erscheint, fügt ihr nun den im API-Explorer generierten Body ein (siehe oben).
-
Ihr könnt nun eure Angaben direkt mit einem Klick auf Execute Workflow testen.
Viele Daten?
Viele Daten?
Wenn ihr mehr als wenige hundert Kontakte in CiviCRM habt, oder viele Datenfelder verarbeiten wollt, solltet ihr nicht alle Daten auf einmal anfragen, sondern mit Pagination arbeiten. Dies lässt sich im API-Explorer konfigurieren und in n8n so berücksichtigen.
E: Knoten für die Separation von Zeilen anlegen
Der Output des vorherigen Knotens ist standardmäßig ein json Objekt, das die Daten als Liste als Wert des keys values enthält. Der Knoten-Typ Split Out ermöglicht es uns, diese Liste, bzw. deren Einträge zu isolieren.
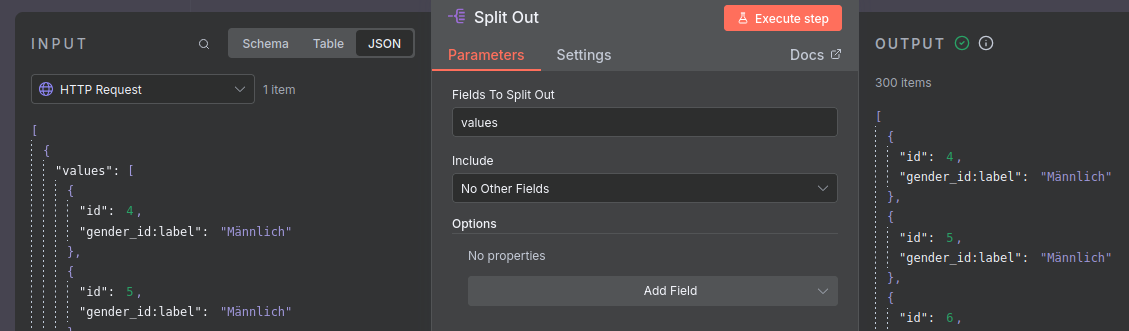
Die Konfiguration dieses Knotens ist simpel: füllt das Feld Values to Split Out einfach mit dem Wert values.
F: Knoten für das Laden der Daten in die managed Datenbank anlegen
Dieser letzte Knoten ist für das Laden der Daten in die managed Datenbank auf Neon, unser Data Warehouse, zuständig.
-
Legt zunächst ein Credential für Postgres an. Wie dies funktioniert, ist hier beschrieben. Die notwendigen Informationen findet ihr in der Neon Konsole.
-
Wenn ihr dies erledigt habt, nutzt den Knoten-Typ für Postgres: Insert or update rows in a table und konfiguriert ihn so wie im Bild unten.
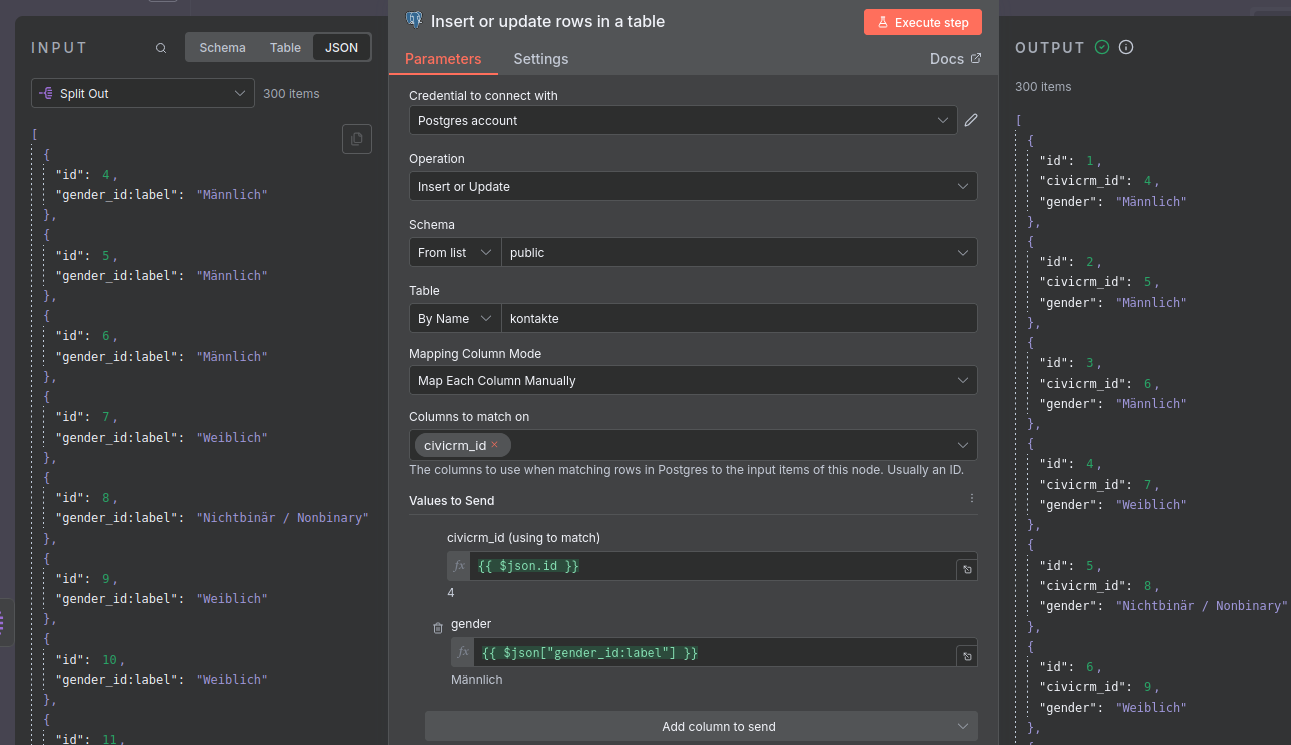
Bei der Zuordnung der Felder aus der API zu den Spalten der Tabelle ist wichtig, dass es einen Unterschied zwischen id und civicrm_id gibt. Ersteres wird automatisch durch die Datenbank erstellt, zweiteres erlaubt Updates von bereits vorhanden Kontakten durch die Referenz dieser. So wird sichergestellt, dass bei erneutem Laden der Daten keine Duplikate entstehen, sondern vorhandene Reihen geupdatet werden.
Full Load
Full Load
In den Begriffen des Data Engineering vollziehen wir hier einen regelmäßigen Full Load. Eine alternative wäre ein ressourcensparender Incremental Load, bei dem nur neue Daten geladen werden. Neu könnte mit Bezug auf Kontakte solche meinen, die geupdatet oder tatsächlich neu hinzugekommen sind.
Das Anlegen von Incremental Loads kann jedoch komplex werden, weil sie Informationen wie das Datum eines Updates und die zuverlässige Sortierung von Ergebnissen der Items einer API-Anfrage voraussetzen.
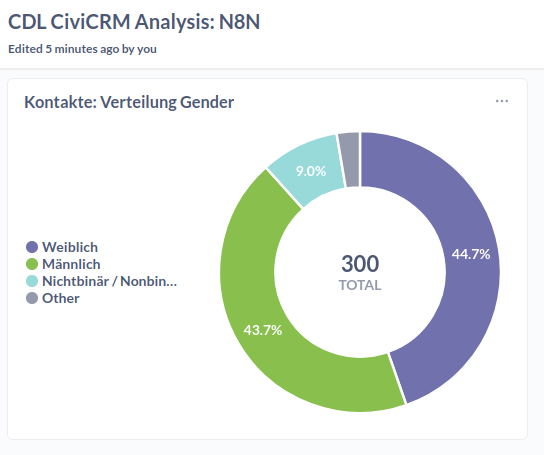
G: Visualisierung in Metabase
-
Verbindet wie hier beschrieben die Datenbank mit Metabase. An die notwendigen Informationen kommt ihr ähnlich wie beim Anlegen der Postgres Credentials für den letzten Knoten des Workflows.
-
Lest euch den Abschnitt zu Visualisierung in Metabase durch. Die obige Visualisierung ist ein Pie-Chart, für den die Daten mit der Summarize Funktion verarbeitet wurden, indem die Reihen pro Gender gezählt wurden.
Fazit
Mit dem vorgestellten Tool-Setup lässt sich der Use Case ohne Code umsetzen, in dem viel Komplexität abstrahiert und versteckt wird. Für simple Use Cases reicht das obige Setup aus. Die Funktionalitäten von n8n sind für anspruchsvollere Data Orchestration jedoch begrenzt.
Ein wesentlicher Nachteil ist die deutlich langsamere Iteration beim Debugging: Workflows müssen komplett durchlaufen werden, Zwischenschritte sind schwer inspizierbar, und es fehlen Debugging-Tools wie Breakpoints oder detaillierte Logs. Zudem ist das Setup weniger transparent als code-basierte Lösungen – Versionskontrolle via Git, Code Reviews und Knowledge Transfer sind schwieriger, da Tool-spezifisches Wissen erforderlich ist. Die Flexibilität ist eingeschränkt, wenn komplexe Transformationslogik benötigt wird, die über die verfügbaren Nodes hinausgeht. Schließlich entsteht ein Vendor Lock-in: Eine Migration zu anderen Tools ist aufwendig, und man ist abhängig von der Weiterentwicklung der eingesetzten Produkte.
ETL mit Kestra - Spender:innenwanderungen über die Zeit
Wir orchestrieren einen ETL-Prozess (Extract, Transform & Load) mit Kestra um die Frage zu beantworten, wie sich Spender:innentypen über die Zeit entwickeln. Dazu aggregieren wir Daten über die CiviCRM API und laden sie täglich in eine Datenbank, um die Entwicklung mit einem Line-Chart zu visualisieren.
🧹 daten-organisieren: CiviCRM API Explorer & Neon; CiviCRM API & Kestra
🔢 daten-auswerten: Metabase
📊 daten-visualisieren: Metabase
Voraussetzungen
- Account bei Neon
- API-Token für eine CiviCRM-Instanz
- Kestra-Instanz oder ein Abonnement des Kestra SaaS
- Metabase-Instanz oder ein Abonnement des Metabase SaaS
- Benutzerdefiniertes Datenfeld Donor Type in CiviCRM
Anleitung
Dieser Ansatz besteht aus 5 Komponenten , die wir nacheinander vorbereiten.
A: Erweiterung der CiviCRM Datenfelder
Wie hier beschrieben, benötigen wir ein neues benutzerdefiniertes Datenfeld, das den Typ einer spendenden Person erfasst. Für Demonstrationszwecke halten wir es simpel und legen das Feld Donor Type als Auswahlliste mit den Optionen One Time Donor, Monthly Donor und Past Donor an. Die Benennung ist dabei beliebig veränderbar und es könnten auch mehr Optionen genutzt werden.
Für unseren Test erstellen wir programmatisch Testdaten mit diesem Datenfeld. In der Realität müsst ihr dieses neue Feld jedoch in eure Erfassung von Kontakten integrieren, oder die Information anderweitig erfassen. Eine Option ist zum Beispiel die Nutzung von Gruppen für Kontakte. Auf Englisch ist dies hier dokumentiert. Ihr könntet Gruppen mit Kriterien wie ist zu einer Contribution zugeordnet anlegen.
B: Anlegen einer Tabelle in der Managed Datenbank (Neon)
Option 1: GUI
Erstelle eine neue Tabelle (wie hier beschrieben):
- Gebe der Tabelle den Namen
spendende_typen_agg - Füge die Spalte
timestampmit dem Datentyptimestampund dem ConstraintNot nullhinzu - Füge für jeden Spender:innentyp eine Spalte hinzu (z.B.
nicht_spendend,einmalig,monatlich,ehemalig) - Wähle für diese Spalten den Datentyp
integerund den ConstraintNot nullaus
Constraints
Constraints
Constraints sind Regeln, die die Datenintegrität und -konsistenz gewährleisten, indem sie festlegen, welche Daten wie in Tabellen gespeichert werden dürfen. Sie dienen als Datenvalidierungsprüfungen auf Ebene der Datenbank.
Option 2: SQL-Editor
Die Tabelle lässt sich im SQL-Editor von Neon durch das Ausführen des folgenden Codes erstellen:
CREATE TABLE IF NOT EXISTS "spendende_typen_agg" (
"id" integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY (
sequence name "spendende_typen_agg_id_seq"
),
"timestamp" timestamp NOT NULL,
"nicht_spendend" integer NOT NULL,
"monatlich" integer NOT NULL,
"einmalig" integer NOT NULL,
"ehemalig" integer NOT NULL
);
Diesen und anderen SQL-Code findet ihr auch im Repository in dem Ordner supporting_code/sql.
C: Datenmodellierung im API-Explorer von CiviCRM
Navigiert zum API Explorer und wählt als Entität Contact, sowie als Aktion get aus. Hier besteht die Datenmodellierung nun aus einer Aggregation nach dem Typ der spendenden Person.
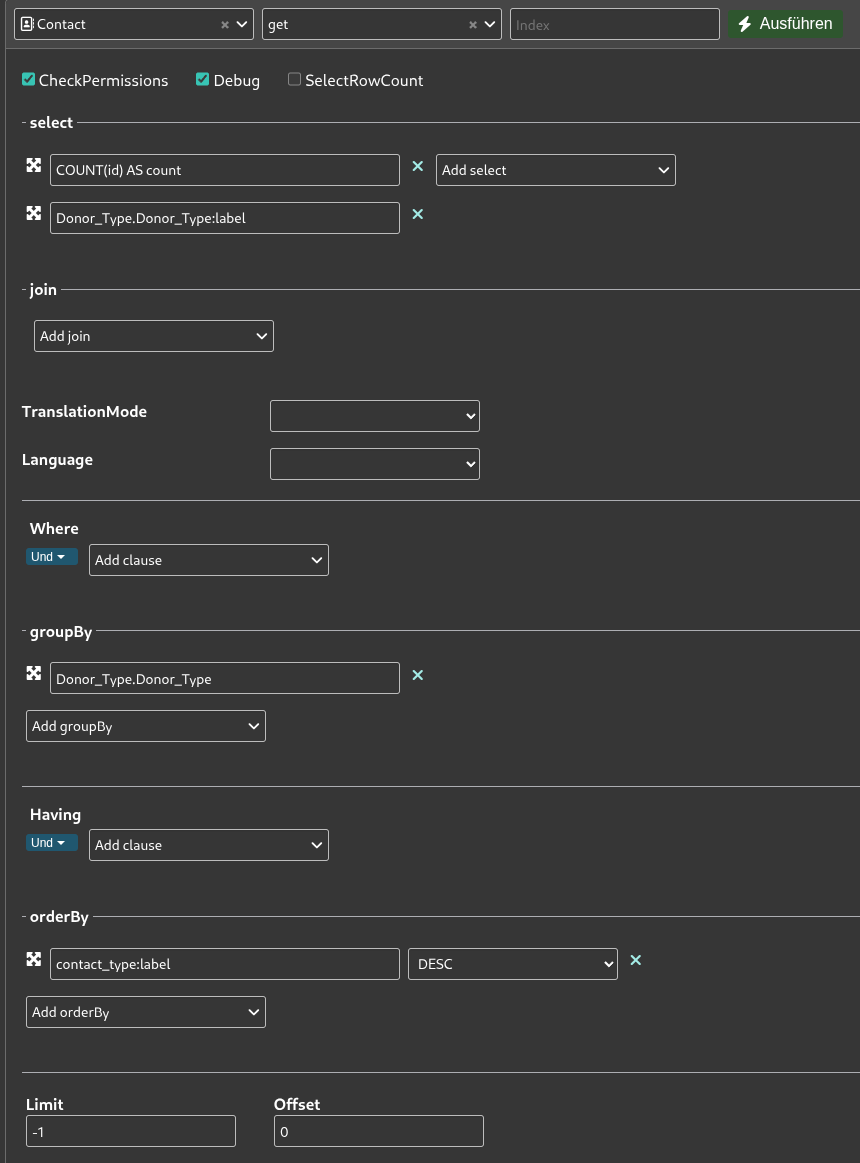
Konfiguriert die API-Anfrage so wie in dem Screenshot oben:
- Wählt unter select die Felder
COUNT(id) AS countundDonor_Type.Donor_Type:labelaus - Nutzt die groupBy Funktion, um die Reihen nach
Donor_Type.Donor_Typezu gruppieren - Sortiert die Ergebnisse unter orderBy nach
contact_type:labelin absteigender Reihenfolge (DESC)
Nach diesen Schritten könnt ihr bereits den Request Body weiter unten unter REST kopieren. Dies sollte in etwa so aussehen:
params=%7B%22select%22%3A%5B%22COUNT%28id%29%20AS%20count%22%2C%22Donor_Type.Donor_Type%3Alabel%22%5D%2C%22orderBy%22%3A%7B%22contact_type%3Alabel%22%3A%22DESC%22%7D%2C%22groupBy%22%3A%5B%22Donor_Type.Donor_Type%22%5D%7D
D: Anlegen des Flows in Kestra
Erstellt einen neuen Workflow auf eurer Kestra-Instanz. Der vollständige Flow als YAML:
id: civicrm_donor_type_count_warehouse
namespace: company.team
tasks:
- id: request
type: io.kestra.plugin.core.http.Request
uri: "{{ secret('CIVICRM_API_URI') }}"
headers:
X-Civi-Auth: "Bearer {{ secret('CIVICRM_API_TOKEN') }}"
method: POST
contentType: application/x-www-form-urlencoded
body: |
params=%7B%22select%22%3A%5B%22COUNT%28id%29%20AS%20count%22%2C%22Donor_Type.Donor_Type%3Alabel%22%5D%2C%22orderBy%22%3A%7B%22contact_type%3Alabel%22%3A%22DESC%22%7D%2C%22groupBy%22%3A%5B%22Donor_Type.Donor_Type%22%5D%7D
- id: to_rows
type: io.kestra.plugin.transform.jsonata.TransformValue
from: "{{ outputs.request.body }}"
expression: |
[{
"nicht_spendend": $sum(values[$."Donor_Type.Donor_Type:label" = null].count),
"ehemalig": $sum(values[$."Donor_Type.Donor_Type:label" = "Past Donor"].count),
"monatlich": $sum(values[$."Donor_Type.Donor_Type:label" = "Monthly Donor"].count),
"einmalig": $sum(values[$."Donor_Type.Donor_Type:label" = "One Time Donor"].count)
}]
- id: insert_agg
type: io.kestra.plugin.jdbc.postgresql.Query
url: "jdbc:postgresql://{{ secret('CIVICRM_NEON_WAREHOUSE_HOST') }}:5432/main"
username: "{{ secret('CIVICRM_NEON_WAREHOUSE_USER') }}"
password: "{{ secret('CIVICRM_NEON_WAREHOUSE_PW') }}"
sql: |
INSERT INTO spendende_typen_agg(timestamp, nicht_spendend, ehemalig, monatlich, einmalig)
SELECT NOW(), nicht_spendend, ehemalig, monatlich, einmalig
FROM jsonb_to_recordset('{{ outputs.to_rows.value }}'::jsonb)
AS t(nicht_spendend int, ehemalig int, monatlich int, einmalig int);
fetchType: NONE
triggers:
- id: schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: 0 0 * * 0
Diesen und andere Kestra-Flows findet ihr auch im Repository in dem Ordner supporting_code/kestra_flows
1. Knoten für die API-Anfrage
Der erste Knoten enthält die API-Anfrage:
- Fügt unter
uriam Anfang die URL eurer Instanz ein. Im API Explorer unter dem Reiter REST ist dies auch als VariableCRM_URLdefiniert - Fügt euer API-Token als Secret ein (siehe oben)
- Im Feld
bodyfügt ihr den im API-Explorer generierten Body ein (siehe oben)
Ein Beispiel-Output der API-Anfrage ist:
{
"values": [
{"count": 22, "Donor_Type.Donor_Type:label": null},
{"count": 76, "Donor_Type.Donor_Type:label": "One Time Donor"},
{"count": 117, "Donor_Type.Donor_Type:label": "Past Donor"},
{"count": 91, "Donor_Type.Donor_Type:label": "Monthly Donor"}
],
"entity": "Contact",
"action": "get",
"debug": null,
"version": 4,
"count": 4,
"countFetched": 4
}
2. Knoten für die Verarbeitung mit JSONata
JSONata ist eine Sprache für die Abfrage und Verarbeitung von JSON-Daten. In diesem Fall transformieren wir die API-Antwort in ein Format, das sich direkt in unsere Datenbank-Tabelle einfügen lässt.
Der JSONata-Knoten nutzt die Expression:
[{
"nicht_spendend": $sum(values[$."Donor_Type.Donor_Type:label" = null].count),
"ehemalig": $sum(values[$."Donor_Type.Donor_Type:label" = "Past Donor"].count),
"monatlich": $sum(values[$."Donor_Type.Donor_Type:label" = "Monthly Donor"].count),
"einmalig": $sum(values[$."Donor_Type.Donor_Type:label" = "One Time Donor"].count)
}]
So funktioniert die Expression:
- Filtern:
values[$."Donor_Type.Donor_Type:label" = "Past Donor"]durchsucht das Arrayvaluesund filtert nur die Objekte, deren Label dem gesuchten Typ entspricht - Extrahieren:
.countgreift auf dascount-Feld der gefilterten Objekte zu - Aggregieren:
$sum()summiert alle gefundenen Werte (relevant wenn mehrere Matches existieren) - Strukturieren: Die eckigen Klammern
[]erstellen ein Array mit einem einzelnen Objekt, dessen Keys (nicht_spendend,ehemalig, etc.) den Spaltennamen in unserer Datenbank entsprechen
Beispiel-Output:
{ "ehemalig": 117, "einmalig": 76, "monatlich": 91, "nicht_spendend": 22 }
3. Knoten für das Laden der Daten in die Managed Datenbank
Dieser letzte Knoten ist für das Laden der Daten in die Managed Datenbank auf Neon, unser Data Warehouse, zuständig:
- Legt zunächst ein Secret für Postgres an. Die notwendigen Informationen findet ihr in der Neon Konsole
- Konfiguriert den Knoten so, dass die transformierten Daten als neue Zeile mit dem aktuellen Timestamp in die Tabelle
spendende_typen_aggeingefügt werden
Wenn ihr Kestra selbst hostet, könnt ihr API Tokens etc. als Secrets über Environment Variables anlegen.
Die SQL-Query im Detail:
INSERT INTO spendende_typen_agg(timestamp, nicht_spendend, ehemalig, monatlich, einmalig)
SELECT NOW(), nicht_spendend, ehemalig, monatlich, einmalig
FROM jsonb_to_recordset('{{ outputs.to_rows.value }}'::jsonb)
AS t(nicht_spendend int, ehemalig int, monatlich int, einmalig int);
So funktioniert die Query:
INSERT INTO spendende_typen_agg(...): Definiert in welche Tabelle und Spalten die Daten eingefügt werdenNOW(): Erzeugt den aktuellen Timestamp für die Zeile, sodass wir später nachvollziehen können, wann diese Daten erfasst wurdenjsonb_to_recordset(...): Konvertiert das JSON-Objekt aus dem vorherigen Knoten in eine relationale Tabellenstruktur'{{ outputs.to_rows.value }}': Kestra-Syntax um auf den Output desto_rows-Knotens zuzugreifenAS t(nicht_spendend int, ...): Definiert das Schema der temporären Tabelletmit den entsprechenden Spaltentypen
Regelmäßige Snapshots
Regelmäßige Snapshots
In den Begriffen des Data Engineering vollziehen wir hier regelmäßige Snapshots. Bei jeder Ausführung wird eine neue Zeile mit den aktuellen Zählungen der verschiedenen Spender:innentypen angelegt. So können wir die Entwicklung über die Zeit nachvollziehen.
H: Visualisierung in Metabase
-
Verbindet wie hier beschrieben die Datenbank mit Metabase. An die notwendigen Informationen kommt ihr ähnlich wie beim Anlegen der Postgres Credentials für den letzten Knoten des Workflows
-
Lest euch den Abschnitt zu Visualisierung in Metabase durch. Die Visualisierung ist ein Line-Chart, der die Entwicklung der verschiedenen Spender:innentypen mit jeweils einer Linie über die Zeit darstellt. Nutzt die Spalte
timestampfür die X-Achse und die verschiedenen Typen-Spalten für die Y-Achse
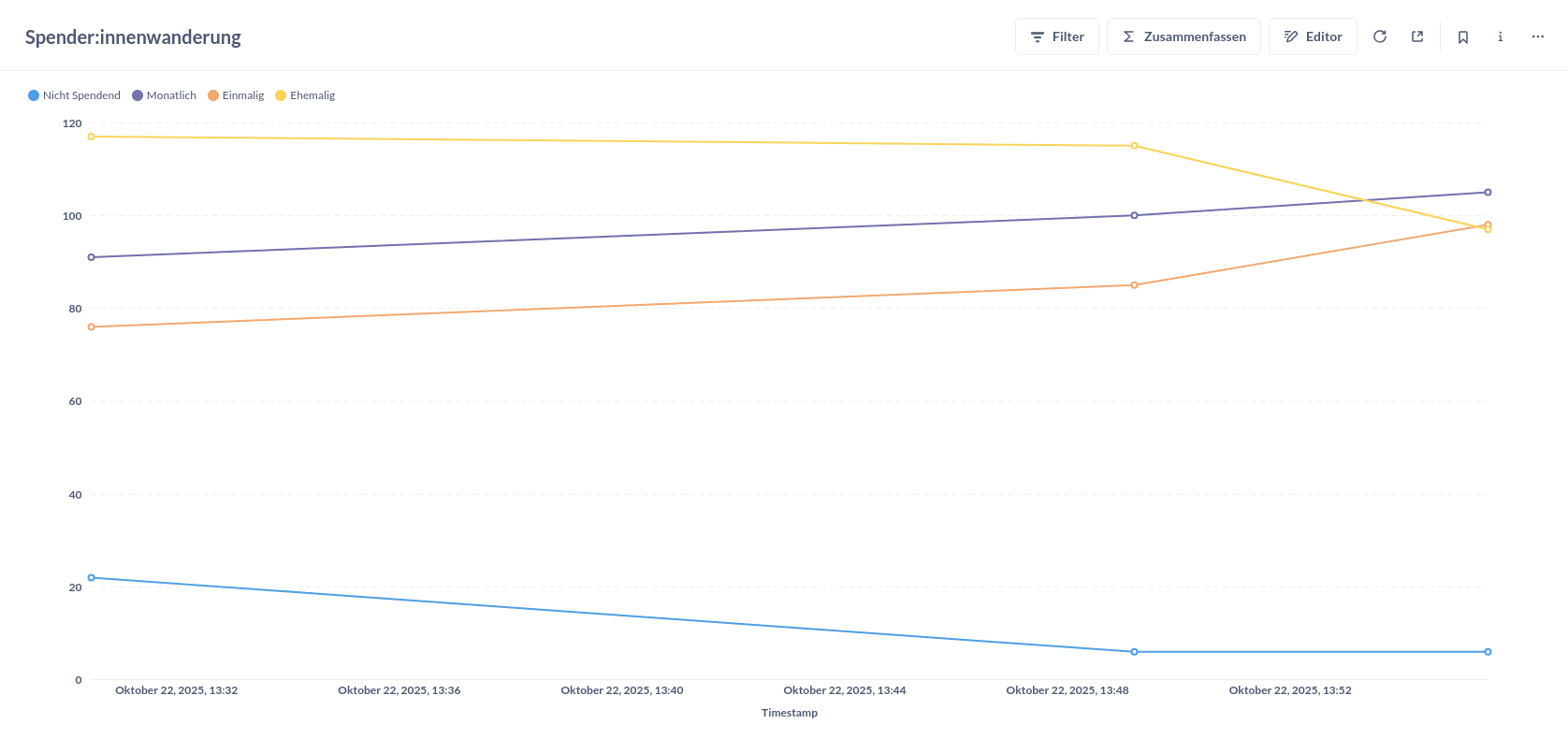
Fazit
Es lässt sich ein ähnliches Fazit wie für den Abschnitt zu ETL mit n8n ziehen. Ein Unterschied ist die Erforderniss der Erweiterung der CiviCRM-Datenfelder, um das Informationen zu Spender:innen zu erfassen.
Kestra als Workflow Tool benötigt im Vergleich zu n8n deutlich mehr technische Skills. Ein wesentlicher Vorteil ist die Versionierbarkeit: Flows werden als YAML-Dateien definiert und können in Git-Repositories gespeichert werden, was Code Reviews, Knowledge Transfer und Zusammenarbeit im Team erheblich erleichtert. Zudem bietet Kestra deutlich mehr Flexibilität – die Code-Umgebung ist erweiterbar, und es stehen umfangreiche Transformationsmöglichkeiten zur Verfügung.
Tools
- CiviCRM-interne Tools
- Excel, Google Sheets & Co. 🔢📊💬🧹
- Business Intelligence Tools🔢📊💬
- Managed Datenbank🧹
- Workflow Automation Tools🔢🧹
- Python & R🔢📊💬🧹
- Self-Hosting
Legende
🧹 daten-organisieren
🔢 daten-auswerten
📊 daten-visualisieren
💬 daten-kommunizieren
(siehe auch Datenlebenszyklus)
CiviCRM-interne Tools
Es lässt sich wiederholen: CiviCRM ist primär ein CRM, kein Datenanalyse- oder Visualisierungstool. Da jedoch externe Tools für mehr Komplexität und Aufwand sorgen, haben wir uns auch mit den Möglichkeiten von CiviCRM selbst beschäftigt.
Unsere Experimente haben wir mit unserer selbst gehosteten Basisinstallation von CiviCRM 6.4.0. durchgeführt. Zwischen der Standalone-Version von CiviCRM und dessen Nutzung in Kombination mit CMS wie Drupal oder Wordpress gibt es Unterschiede. Auch Spezifika von Hosting-Anbietern (z.B. Systopia-eigene Extensions) konnten wir nicht berücksichtigen.
Erweiterung der Datengrundlage
Um Daten auf eine bestimmte Fragestellung hin zu analysieren, benötigt man zunächst dafür geeignete Daten. CiviCRM bietet eine vernünftige Auswahl an Standard-Feldern für die unterschiedlichen Datenklassen (Kontakte etc.). Man kann diese jedoch um Eingabefelder erweitern, sollte man zusätzliche Informationen benötigen.
Tags
Eine einfache Art, Kontakte in Bezug auf Art der Unterstützung zu visualisieren ist, ihnen Tags zuzuordnen. Tags lassen sich in den Einstellungen von CiviCRM erstellen und dann bei der Erstellung von Kontakten setzen. Es lassen sich außerdem Gruppen von Überkategorien festlegen. So kann man als Überkategorie z.B. “Donor Type” erstellen und als dieser Kategorie zugeordnet “One Time Donor”, “Monthly Donor” und “Past Donor”. Die Benennung der Tags ist dabei beliebig. Es ist wichtig, beim Erstellen der Tags die Überkategorie auf nicht auswählbar zu setzen. Beim Import von Kontakten lassen sich nur alle in einem Importierungsvorgang enthaltenen Kontakte zusammen taggen.
Benutzerdefinierte Felder
Eine andere Art CiviCRM Erfassungsmöglichkeiten zu erweitern ist das Anlegen von benutzerdefinierten Feldern. Hierfür muss man zunächst eine Gruppe anlegen und dann ein Feld hinzufügen. In der CiviCRM Dokumentation ist dies hier erklärt.
CiviCRM-Datenbank
Hinter CiviCRM als Software liegt eine relationale SQL-Datenbank1, in der die Daten in zahlreichen Tabellen gespeichert sind. So sind Daten in CiviCRM bereits sehr gut organisiert und verwaltet. Der Zugriff auf die SQL-Datenbank ermöglicht einen direkten Zugriff auf die Daten in CiviCRM. Dies ist v.a. nützlich für andere Komponenten, die einen dauerhaften und beständigen Datenzugriff benötigen.
-
Eine Erklärung des Begriffs “Datenbank” gibt es im Selbstlernmaterial des Civic Data Labs. Relevant für das Verständnis von CiviCRM auch der Abschnitt “Mehr zu Datenbanken”. ↩
CiviCRM-API & API-Explorer
CiviCRM API
CiviCRM hat eine Programmierschnittstelle (Application Programming Interface / API1), welche wir verwenden, um von extern auf CiviCRM-Daten zuzugreifen.
CiviCRM has a stable, comprehensive API (Application Programming Interface) for accessing and managing data. The API is the recommended way for any extension or external program to interact with CiviCRM. CiviCRM also uses its own API to power all new UIs and bundled extensions.2
In der Basisinstallation gibt es für jeden Datentyp in CiviCRM eine sogenannte Entität (en: Entity):
- Kontakte ->
Contact - Aktivitäten ->
Activity - Veranstaltungen ->
Event - Zuwendungen ->
Contribution - Emails ->
Email - uvm.
Jede Entität hat wiederum sogenannte Aktionen, die man mithilfe der API auf ihr ausführen kann. Zum Beispiel kann man Kontakte erstellen (create) oder löschen (delete). Für den Datenzugriff am relevantesten ist die Aktion get, mithilfe der man Dateneinträge abfragen kann.
Aus der Kombination von Entität und Aktion ergeben sich die API-Endpunkte. Hier sind Endpunkte, die wir im Rahmen unserer Experimente verwendet haben:
- Liste von Kontakten:
https://civicrm.correlaid.org/civicrm/ajax/api4/Contact/get - Liste von in SearchKit abgespeicherten Suchen:
https://civicrm.correlaid.org/civicrm/ajax/api4/SavedSearch/get - Die Ergebnisse einer gespeicherten SearchKit Suche herunterladen:
https://civicrm.correlaid.org/civicrm/ajax/api4/SearchDisplay/download
Um Zugriff auf die API zu erhalten, kontaktiert am besten euren CiviCRM-Dienstleister. Wenn ihr CiviCRM selbst hostet und administriert, folgt der Dokumentation.
Anleitungen
API einrichten
Die Konfiguration der API und die Einrichtung von API-Schlüsseln in CiviCRM ist etwas ungewöhnlich und erfordert mehrere Schritte:
- Erweiterung installieren: Zuerst muss die Erweiterung für API-Schlüssel installiert werden. Diese ist unter folgendem Link verfügbar: https://civicrm.correlaid.org/civicrm/admin/extensions?action=update&id=com.cividesk.apikey&key=com.cividesk.apikey
- API-Schlüssel erstellen: Anschließend muss ein API-Schlüssel für einen bestimmten Kontakt erstellt werden.
- Kontakt zu einer Gruppe hinzufügen: Der Kontakt, für den der Schlüssel erstellt wurde, muss einer Gruppe hinzugefügt werden (z. B. der Gruppe „Administratoren“).
- REST-Authentifizierung konfigurieren: Abschließend muss die REST-Authentifizierung konfiguriert werden. Dies erfolgt über den folgenden Link: https://civicrm.correlaid.org/civicrm/admin/setting/authx?reset=1 . Dort müssen die „Authentication Guards“ entfernt und die API-Schlüssel-Methode als erforderliche Authentifizierungsmethode für die relevanten Felder hinzugefügt werden.
API Explorer
🧹 daten-organisieren 🔢 daten-auswerten
Da die Dokumentation der CiviCRM API für Nicht-PHP-Entwickler*innen nicht besonders zugänglich ist, fanden wir es hilfreich, mit dem API-Explorer zu arbeiten. Im API-Explorer kann man mithilfe einer grafischen Benutzeroberfläche direkt in CiviCRM Abfragen an die API konfigurieren und ausprobieren. Das erleichtert es enorm, ...
- ... die richtigen Endpunkte zu finden
- ... zu sehen, wie der
bodybei POST-Requests übergeben wird (siehe unten) - ... die Anfrage so anzupassen, dass sie die gewünschten Daten liefert
Wenn ihr selbst mit der API arbeiten möchtet, ist der API-Explorer ein gutes Werkzeug, um euch in der Entwicklung eurer Lösung zu unterstützen.
In der Basisinstallation findet ihr den API-Explorer unter Unterstützung -> Entwickler -> API-Explorer. Sonst fragt euren CiviCRM-Hosting-Dienstleister.
Anleitungen
POST-Request-Parameter aus dem API-Explorer nutzen
Bei POST-Requests an die CiviCRM API kann ein einzelnes Feld namens params verwendet werden , das eine URL-encoded JSON-Zeichenkette der API-Parameter enthält. URL-Encoding wandelt Sonderzeichen in ein Format um, das sicher in URLs und Formulardaten übertragen werden kann (z.B. wird { zu %7B). Dies ermöglicht es, komplexe JSON-Strukturen als einzelnes Formularfeld im POST-Body zu senden, das CiviCRM dann dekodiert und als API-Parameter verarbeitet.
Wenn man im API-Explorer eine API-Anfrage konfiguriert hat, hier als Beispiel die Übergabe aller Kontakte, lässt sich weiter unten auf der Seite des API-Explorers der Reiter "REST" auswählen. Hier wird dann für unser Beispiel angezeigt:
curl -X POST -H "$CRM_AUTH" "$CRM_URL" \^
-d 'params=%7B%22limit%22%3A25%7D'
Nützlich für API-Anfragen mit anderen Tools ist der folgende Teil des Codes: params=%7B%22limit%22%3A25%7D. Beachtet, dass die Anführungszeichen nicht mitkopiert werden sollten.
-
Eine Erklärung des Begriffs "API" gibt es im Selbstlernmaterial des Civic Data Labs. Es gibt eine API-Dokumentation (Englisch), die einen guten Überblick gibt über die API v4. Allerdings ist die Dokumentation sehr auf PHP ausgerichtet und bei weitem nicht alle Routen + Endpunkte sind dort dokumentiert. ↩
CiviCRM SearchKit & ChartKit
SearchKit und ChartKit sind direkt in CiviCRM integrierte Tools für die Auswertung und Visualisierung von CiviCRM-Daten.
SearchKit
CiviCRM SearchKit ist eine Erweiterung für CiviCRM, die es Nutzer*innen ermöglicht, komplexe Abfragen an ihre Daten zu stellen. Als Nutzer*in kann man filtern, aggregieren, Felder auswählen und gruppieren.
Um sich mit SearchKit vertraut zu machen, empfiehlt es sich, mit einfachen Auswertungen (z.B. "Zählen" von Kontakten nach Kategorie) zu starten und das Komplexitätslevel nach und nach zu starten.
Eine (englischsprachige) Einführung in SearchKit findet sich in der CiviCRM Dokumentation. Auf dem YouTube-Channel von CiviCRM gibt es eine Playlist zu SearchKit.
Vorteile
- mächtiges Analysewerkzeug: ihr könnt verschiedene CiviCRM-Datentypen kombinieren, Einträge filtern, relevante Felder auswählen und Kennzahlen wie Anzahl, Mittelwerte, etc. (aggregiert) ausrechnen
- Zugriff auf Ergebnisse über die API: Ihr könnt Daten in SearchKit aggregieren und über die API in andere Tools einbinden. So habt ihr immer die aktuellen Ergebnisse eurer SearchKit-Suchen verfügbar und könnt mit ihnen weiterarbeiten.
Nachteile
- Das Arbeiten mit SearchKit erfordert eine Einarbeitung in datenorientiertes Denken. SearchKit orientiert sich stark an Konzepten von SQL1, was für Personen, die sich nicht damit auskennen, erst einmal herausfordernd sein kann.
- Das User Interface ist nicht immer intuitiv.
- Bestimmte Transformationen (z.B. Pivotieren) sind nicht möglich.
Fazit
SearchKit erfordert etwas Einarbeitung, aber dann ist es eine gute und mächtige Option um innerhalb von CiviCRM Daten (deskriptiv) auszuwerten. Die Option, die Ergebnisse über die API abzurufen, eröffnet einen vielversprechenden Lösungsraum insb. für einfache deskriptive Auswertungen wie Output-Monitoring etc., in dem Daten in CiviCRM ausgewertet und aggregiert werden und in einem externen Tool visualisiert werden. Bei datenschutzsensibler und verantwortungsbewusster Aggregation der Daten in SearchKit können dann ggf. auch Tools von US-Anbietern zur Weiterverarbeitung verwendet werden, ohne den Datenschutz zu kompromittieren.
ChartKit
Mit ChartKit kann man basierend auf SearchKit-Suchen einfache Grafiken wie Balken-, Linien- oder Tortendiagramme erstellen. Konzeptionell sind ChartKit-Visualisierungen eine weitere Möglichkeit, Ergebnisse von SearchKit-Suchen darzustellen ("Search Display"). Für jede Suche können mehrere Visualisierungen erstellt werden.
Um euch mit ChartKit vertraut zu machen, könnt ihr anhand einer einfachen Suche verschiedene Visualisierungen erstellen.
ChartKit sollte bei neueren Versionen von CiviCRM vorinstalliert sein. Sonst wendet euch an euren Hosting-Dienstleister.
Vorteile
- ChartKit ist direkt in SearchKit integriert und Visualisierungen sind direkt in CiviCRM gespeichert
- grafische Benutzeroberfläche ist relativ verständlich
- ausreichende Auswahl an Visualisierungen
- ein Button zum Download als PNG oder SVG kann hinzugefügt werden -> praktisch
- wird aktiv weiterentwickelt (z.B. Talk beim CiviCamp Hamburg 2024)
Nachteile
- man kann nicht alle Aspekte der Visualisierungen anpassen (z.B. Farben, bestimmte Marker, ...)
- Visualisierungen können nicht über einen Link mit Externen geteilt, in eine Website eingebettet oder über die API abgerufen werden.
- Visualisierungen sind "Anhängsel" von SearchKit Suchen und können nicht anders sortiert oder angeordnet werden.
Fazit
ChartKit ist eine gute Option, wenn ihr Datenvisualisierungen v.a. für den internen Gebrauch oder für Berichte ohne große Design-Anforderungen nutzen möchtet. Der Export-Button direkt in der Visualisierung ist sehr praktisch. Es bestehen (noch) Einschränkungen bei der Verfeinerung der Visualisierungen sowie bei der Teilbarkeit aus CiviCRM hinaus. Wenn ihr ansprechendere oder komplexere Visualiserungen oder Dashboard-Funktionalitäten benötigt, solltet ihr daher auf externe Tools zurückgreifen.
-
Eine Erklärung des Begriffs "SQL" gibt es im Selbstlernmaterial des Civic Data Labs. ↩
Reports/Berichte und Dashlets
Diese Seite wurde von ChatGPT erstellt und redaktionell und inhaltlich überarbeitet und erweitert.
CiviCRM Reports sind vorgefertigte oder individuell erstellbare Auswertungen, mit denen ihr eure Daten aus CiviCRM (z. B. Kontakte, Spenden, Mitgliedschaften, Events) analysieren könnt. Berichte bieten Filter- und Gruppierungsoptionen und können gespeichert, exportiert und auch automatisiert per E-Mail verschickt werden.
CiviCRM-Dashlets sind kleine Dashboardmodule (Widgets) auf dem CiviCRM-Dashboard (der Startseite eurer CiviCRM-Instanz), Diese Module können wichtige Kennzahlen, Listen oder Diagramme anzeigen. So könnt ihr einen Überblick über wichtige Daten erhalten, ohne groß navigieren zu müssen.
Vorteile Reports/Berichte
- standardisierte Vorlagen
- können als CSV oder direkt als PDF exportiert werden
- Versand via Mail möglich
- einfache Möglichkeit, um "Listen" zu bekommen
- können über Dashlets (s.u.) ins Dashboard integriert werden
Nachteile Reports/Berichte
- Komplexe oder mehrdimensionale Analysen sind nur bedingt umsetzbar
- Anpassungen erfordern teils technisches Wissen oder Erweiterungen
- nicht so flexibel und mächtig wie SearchKit
- Ergebnisse können nicht über die API v4 exportiert werden
Vorteile Dashlets
- Schneller benutzerfreundlicher Überblick: Wichtige Kennzahlen und Trends sind sofort sichtbar. Kein Umweg über Menüs oder Berichte nötig.
- Ihr könnt eigene Berichte als Dashlets einbinden.
- Visuelle Darstellung von Echtzeit-Daten
Nachteile Dashlets
- Es sind nur oberflächliche Analysen (einfache Kennzahlen, Balken- und Tortendiagramme, Listen) möglich – keine komplexen Auswertungen.
- Eingeschränkte Visualisierung: Grafiken sind funktional, aber optisch und interaktiv recht einfach.
- Zu viele Dashlets können die Dashboard-Performance verlangsamen.
- Individuelle oder dynamische Visualisierungen erfordern Entwicklungsaufwand.
Fazit
CiviCRM-Berichte sind gut geeignet, um in CiviCRM Überblick zu bekommen über operative Abläufe und Kennzahlen. Berichte eignen sich auch für die Erstellung von Datensätzen zur weiteren Verarbeitung in anderen Tools (z.B. Excel). Allerdings können diese Datensätze dann nur manuell exportiert werden, während dies bei SearchKit über die API möglich ist. Generell ist SearchKit und ChartKit
Die Dashlet-Funktion ist praktisch, um bestimmte Übersichten direkt auf der Startseite einzubinden. Für tiefergehende Datenanalysen oder professionelle Visualisierungen (z. B. mit interaktiven Diagrammen oder Data-Dashboards) reichen Berichte/Reports und Dashlets jedoch nicht aus – hier sind externe Tools oder individuelle Erweiterungen gefragt.
Weitere CiviCRM Tools
Neben SearchKit und ChartKit und Reports/Berichten gibt es noch weitere Tools und Erweiterungen in CiviCRM, mithilfe derer ihr Daten analysieren und visualisieren könnt. Hier gehen wir noch auf die Erweiterung Civisualize und spezifische Erweiterungen ein.
Civisualize
Civisualize ist eine CiviCRM Erweiterung, mit der Nutzer*innen Grafiken erstellen können. Für die gängigsten CiviCRM Komponenten wie Kontakte, Zuwendungen, Veranstaltungen und Rundschreiben liefert Civisualize einige Überblicksgrafiken mit. Außerdem gibt es ein Mini-Dashboard für Spendentrends ("Donor Trends"). Eine Beschreibung der schon inkludierten Visualisierungen findet sich hier (Englisch). In der Basis-Installation findet ihr Civisualize unter Berichte -> Civisualize.
Eigene bzw. zusätzliche Grafiken können mithilfe der Javascript Bibliotheken d3.js und dc.js erstellt werden. Diese Funktion richtet sich jedoch primär an Entwickler*innen, die sich mit SQL, der API von CiviCRM und Javascript auskennen.
Vorteile von Civisualize
- Visualisierungen sind integriert in CiviCRM und leicht auffindbar für alle Nutzer*innen
- vorgefertigte Visualisierungen geben einen ersten deskriptiven Einblick in die gängigsten CiviCRM-Datentypen
- Visualisierungen sind prinzipiell interaktiv und erlauben eine rudimentäre Filterung
Nachteile von Civisualize
- ohne tiefergehende technische Kenntnisse können keine eigenen Visualisierungen erstellt werden. Erfordert viel Zeit zur Einarbeitung.
d3.jsist ein ziemlich komplex und die Lernkurve ist steil.1- Visualisierungen können nicht als
pngo.ä. exportiert werden - Dashboards / Visualisierungen können nicht mit Externen geteilt werden
- keine Verknüpfung der Datentypen "out of the box" (Ausnahme: Spendentrends-Dashboard).
Fazit
Civisualize liefert einige potenziell hilfreiche Grafiken "out of the box" und macht diese zugänglich direkt in CiviCRM. Wenn diese vorgefertigten Visualisierungen hilfreich sind für einen ersten Einblick in die Daten für interne Nutzer*innen, kann eine Installation sinnvoll sein. Die Lernkurve, um eigene Datenvisualisierungen zu erstellen, ist zu steil - gerade für nicht-technische Nutzer*innen - um einen Einsatz darüber hinaus zu rechtfertigen, außer es ist zwingend notwendig, dass Visualisierungen direkt in CiviCRM auffindbar sind. Civisualize ist kein Tool, welches eine einfache, zugängliche Analyse von Daten ermöglicht.
Use-Case-spezifsche Extensions
Im Rahmen des Datenvorhabens haben wir uns auf CiviCRM-Komponenten und -Extensions konzentriert, die dediziert auf die Analyse und Visualisierung von Daten ausgelegt sind. Aber auch Extensions, die für spezifische Anwendungsfälle (z.B. Spender*innenanalyse, ...) erstellt wurden, haben z.T. Datenauswertungen und -visualisierungen an Bord. Wir freuen uns über Hinweise zu den Datenkapazitäten von "inhaltlichen" Extensions und nehmen sie gerne in die Liste auf.
Contact Categories
Die Extension Contact Categories bietet die Möglichkeit, Kontakte nach Prioritätsgruppen zu kategorisieren. Prioritätsgruppen können eigenständig konfiguriert werden. Datenanalyse und -visualisierung: Als Datenvisualisierung steht ein Flow-Chart zur Verfügung, der die Übergänge von Kontakten zwischen den verschiedenen Kontaktkategorien visualisiert.
-
Selbst die Entwickler*innen der Extension geben dies zu bedenken: "Be warned, d3 is awesome, but the learning curve is steep." ↩
Excel, Google Sheets & Co.
Mit Tabellenkalkulationsprogrammen wie Excel, Google Sheets und Libre Office Calc könnt ihr Daten erfassen, sie analysieren und grafisch darstellen.
Microsoft Excel
🔢 daten-auswerten 📊 daten-visualisieren 🧹 daten-organisieren
Microsoft Excel ist ein häufig genutztes Tabellenkalkulationsprogramm, mit dem ihr Daten aus CiviCRM oder anderen Quellen strukturieren, analysieren und visualisieren könnt. Ihr könnt damit:
- ... CiviCRM-Daten (z.B. Spenden, Mitglieder oder Events) mithilfe von Pivot-Tabellen, Formeln und Filtern auswerten, um z. B. Spendenentwicklungen zu analysieren oder Zielgruppen zu vergleichen (🔢 daten-auswerten)
- ... mithilfe von Diagrammen die Ergebnisse anschaulich darstellen (📊 daten-visualisieren)
- ... mit Power Query (s.u.) Daten automatisch aktuell halten (🧹 daten-organisieren).
Excel kann sowohl lokal (Desktop-Version) als auch in der Cloud (Excel for the Web) eingesetzt werden.
Vorteile von Excel
- Geringe Einstiegshürde & weit verbreitet: Viele Nutzer*innen kennen Excel bereits, und es entstehen ggf. keine zusätzlichen Kosten, weil Lizenzen bereits vorhanden sind.
- Flexibilität: Excel ermöglicht Datenanalyse, -visualisierung und -management in einem Tool.
- Datenorganisation: in Excel können Daten aus CiviCRM mit Daten aus anderen Quellen zusammengeführt werden
- Integration: Wer die Microsoft Cloud nutzt, kann Excel einfach mit Power BI oder anderen Tools verbinden.
Nachteile von Excel
- "Excel-Parallelwelten": Wenn Nutzer*innen Daten direkt in Excel ändern statt in CiviCRM, entstehen inkonsistente Datenquellen und der Aufwand für die Wiederherstellung einer "Single Source of Truth"1 steigt.
- Datenschutz und Datensouveränität: Bei Excel on the Web müssen Daten mit Microsoft geteilt werden – nicht alle Organisationen möchten / können ihre Daten mit Microsoft teilen.
- Eingeschränkte Visualisierung: Komplexe Dashboards oder maßgeschneiderte Grafiken sind in Excel schwer umsetzbar. Wenn ihr regelmäßiger oder in größerem Umfang auf Dashboards zurückgreifen möchtet, solltet ihr eher auf ein Business Intelligence Tool setzen. Für maßgeschneiderte und komplexere Visualisierungen, die z.B. einmalig für eine Veröffentlichung erstellt werden, sind Programmiersprachen wie Python oder R die beste Wahl.
- Fortgeschrittene Analysen sind in Excel z.T. auch möglich, erfordern aber gute Kenntnis der Funktionen und Formeln. Wenn ihr mittel- bzw. langfristig komplexere Analysemethoden aus dem Bereich Machine Learning2 oder Künstliche Intelligenz3 nutzen möchtet, ist ggf. ein Investment in das Lernen von Python oder R langfristig sinnvoller. Das gleiche gilt für die Analyse von sehr großen Datenmengen (z.B. über 1 Mio. Zeilen).
- Lizenzdschungel: Nicht alle Funktionen sind in jeder Lizenz enthalten. Microsofts Preis- und Lizenzmodelle sind schwer zu durchblicken.
Fazit
Aufgrund seiner Flexibilität ist und bleibt Excel eine gute Option, um diverse Aufgaben rund um die Analyse und Visualisierung von CiviCRM-Daten zu bewältigen. Es ist zugänglich für viele Nutzer*innen. Bei größeren Datenmengen oder höheren Anforderungen an Auswertung, Visualisierung oder Weiterverbreitung von Daten und Ergebnissen sind spezialisierte Tools fast immer eine bessere Wahl.
Excel: Power Query
Power Query ist ein Werkzeug in Excel und Power BI, das Daten aus verschiedenen Quellen (z. B. CiviCRM-API, Datenbanken, Excel-Dateien) importiert, bereinigt und für Analysen aufbereitet. Es automatisiert wiederkehrende Schritte, spart Zeit und reduziert Fehler.
Für die Analyse von CiviCRM-Daten sind v.a. Power Query's Features zum Datenimport relevant. Wir haben Power Query verwendet, um Daten mithilfe der CiviCRM API in Excel zu importieren (siehe unser Experiment zu SearchKit + Excel). Aber auch die anderen Optionen können nützlich sein, z.B. der Import aus anderen Excel-Dateien.
Vorteile von Power Query
- Direkter Datenimport aus CiviCRM mithilfe der CiviCRM API: Ihr könnt Daten automatisch aktualisieren und spart euch den manuellen Schritt des Datenexports aus CiviCRM. Siehe unser Experiment zu SearchKit + Excel.
- Flexibilität: Power Query kann mehr als nur API-Daten laden – eine Einarbeitung lohnt sich.
Nachteile von Power Query
- Nicht ganz einfache Bedienung: Die Benutzeroberfläche ist unübersichtlich, und für fortgeschrittene Funktionen müsst ihr ggf. lernen, in Power Query in der Sprache "M" zu programmieren. Die Dokumentation zu M ist nicht sehr umfangreich und wenn man LLMs um Hilfe fragt, bekommt man manchmal Halluzinationen zurück.
- in Excel für das Web kann man Power Queries nicht bearbeiten, sondern nur ausführen. Das ist unpraktisch, wenn kollaborativ im Browser gearbeitet wird und Queries häufig editiert werden müssen.
- Bewusster Umgang mit Sicherheit nötig: Wenn ihr Power Query verwendet, um mit der CiviCRM API zu kommunizieren, müsst ihr euren CiviCRM API-Schlüssel in der Excel Datei hinterlegen. Das bedeutet, dass ihr diese Datei nicht direkt mit Externen teilen solltet, da diese sonst Zugriff auf euren API-Schlüssel und somit Daten in eurer CiviCRM-Instanz bekommen könnten.
Fazit
Power Query ist eine sinnvolle Option, um CiviCRM-Daten (teil-)automatisch in Excel zu integrieren – das reduziert manuelle Fehler und spart Zeit. Allerdings sollte der Einsatz nur mit einem hohen Bewusstsein für Datensicherheit erfolgen, um API-Schlüssel nicht versehentlich weiterzugeben. Falls bereits (zu) viele Excel-Dateien und -Analysen existieren, hilft Power Query, zentrale Referenzdatensätze zu erstellen, auf die andere Excel-Dateien mit Power Query zugreifen können. Dadurch lassen sich Datenkonsistenz verbessern und Ordnung in die Analyseprozesse bringen.
Google Sheets
Der Text dieses Abschnitts wurde von Mistral erstellt und dann inhaltlich und redaktionell überarbeitet und ergänzt.
🔢 daten-auswerten 📊 daten-visualisieren 🧹 daten-organisieren
Google Sheets ist die kostenlose, webbasierte Tabellenkalkulation von Google Workspace, die sich besonders für kollaborative Datenanalyse eignet. Ihr könnt damit Daten aus CiviCRM oder anderen Quellen analysieren, visualisieren und in Echtzeit gemeinsam bearbeiten.
Vorteile von Google Sheets
- Echtzeit-Kollaboration in der Cloud: Mehrere Nutzer*innen können gleichzeitig an einer Datei in der Cloud arbeiten.
- Einfache Integration: Verbindung mit Google Drive, Data Studio und anderen Google-Diensten.
- Automatisierung: Mit Google Apps Script (s.u.) könnt ihr Daten aus CiviCRM importieren.
Nachteile von Google Sheets
- Performanz bei großen Datensätzen: Bei großen Datenmengen (ab ~100.000 Zeilen) wird Sheets langsam.
- Weniger leistungsfähig als Excel: Komplexe Formeln oder Pivot-Tabellen sind möglich, aber nicht so mächtig.
- Datenschutz und Datensouveränität: Daten werden auf Google-Servern gespeichert – für manche Organisationen keine Option.
Fazit: Google Sheets
Wenn ihr Google Sheets bereits verwendet, ist es eine gute Option, um kollaborativ und cloud-basiert mit euren CiviCRM-Daten zu arbeiten. Sheets eignet sich besonders gut für einfache bis mittelkomplexe Datenauswertungen und Visualisierungen für den internen Gebrauch. Aufgrund der Datenschutzproblematik solltet ihr vermeiden, personenbezogene Daten in Google Sheets zu speichern. Eine Option kann sein, Daten in SearchKit vorab zu aggregieren.
Google Apps Script
Google Apps Script ist eine JavaScript-basierte Programmiersprache, mit der ihr u.a. Abläufe in Google Sheets automatisieren könnt. Mit AppsScript können wir CiviCRM-Daten mithilfe der CiviCRM-API direkt in Google Sheets laden.
Vorteile von Google Apps Script
- Kostenlos und integriert: Keine zusätzliche Software nötig – läuft direkt in Google Sheets.
- Direkter Datenimport aus CiviCRM mithilfe der CiviCRM API: Ihr könnt Daten automatisch aktualisieren und spart euch den manuellen Schritt des Datenexports aus CiviCRM. Siehe unser Experiment zu SearchKit + Google Sheets.
Nachteile von Google Apps Script
- Erfordert Grundkenntnisse in JavaScript.
- Eingeschränkte Performance: Bei komplexen Skripten oder großen Datenmengen kann es langsam werden.
- Abhängigkeit von Google: Skripte laufen nur in der Google Workspace-Umgebung.
Fazit: Google Apps Script
Mit Google Apps Script könnt ihr ähnlich wie mit Power Query Daten von der CiviCRM API und anderen Datenquellen (teil-)automatisiert in Google Sheets laden. So könnt ihr einfache Datenintegrationen selbst umsetzen. Der Einsatz erfordert jedoch Grundkenntnisse in JavaScript. Für komplexe Datenpipelines sind Python, R oder spezialisierte ETL-Tools oft die bessere Wahl.
Alternativen
Libre Office Calc
🔢 daten-auswerten 📊 daten-visualisieren
LibreOffice Calc ist das Tabellenkalkulationsprogramm der kostenlosen Open-Source LibreOffice-Suite – ähnlich wie Microsoft Excel, aber ohne Lizenzkosten und mit offenem Quellcode. Ihr könnt damit Daten analysieren, Berechnungen durchführen, Pivot-Tabellen erstellen und Diagramme generieren. Calc unterstützt gängige Formate wie XLSX und bietet viele Funktionen für Formeln, Filter und Datenvisualisierung, ist aber etwas weniger leistungsstark als Excel bei extrem großen Datenmengen.
Fazit
Wenn ihr auf Open Source setzen wollt, ist Libre Office Calc eine gute und solide Wahl, die euch einen ähnlichen Funktionsumfang bietet in Bezug auf die Analyse und Visualisierung von Daten. Abstriche müsst ihr bei der Integration in Cloud-Umgebungen und bei den Fähigkeiten zur (Teil-)Automatisierung machen - eine wirklich funktionale Power Query oder Apps Script Alternative fehlt nämlich bis jetzt.
OnlyOffice
🔢 daten-auswerten 📊 daten-visualisieren
Eine weitere Alternative ist die Tabellenkalkulation der ONLYOFFICE-Suite, die besonders auf kollaboratives Arbeiten in Echtzeit ausgelegt ist. Ein großer Vorteil gegenüber Libre Office Calc ist die Integration in Cloud-Dienste (z. B. Nextcloud, ownCloud) und die Möglichkeit, Dokumente gleichzeitig mit mehreren Nutzer*innen zu bearbeiten.
-
Single Source of Truth (SSOT) bedeutet, dass alle relevanten Daten an einem zentralen, vertrauenswürdigen Ort gespeichert und gepflegt werden – statt in verschiedenen, möglicherweise widersprüchlichen Quellen. So werden Doppelarbeit, Fehler und Unsicherheiten vermieden, weil alle Teams oder Systeme auf dieselben, aktuellen Informationen zugreifen. ↩
-
Eine Erklärung des Begriffs "Machine Learning" gibt es im Selbstlernmaterial des Civic Data Labs. ↩
-
Eine Erklärung des Begriffs "Künstliche Intelligenz" gibt es im Selbstlernmaterial des Civic Data Labs. ↩
Business Intelligence Tools
🔢 daten-auswerten 📊 daten-visualisieren 💬 daten-kommunizieren
Business Intelligence Tools (BI-Tools) sind Softwarelösungen, die Organisationen dabei unterstützen, Daten zu sammeln, zu analysieren, zu visualisieren und in verwertbare Erkenntnisse umzuwandeln. Sie helfen, fundierte Entscheidungen zu treffen, indem sie komplexe Datenmengen verständlich und zugänglich machen.
Metabase
🔢 daten-auswerten 📊 daten-visualisieren 💬 daten-kommunizieren
Metabase ist eine Open-Source-Software für Business Intelligence, die Organisationen dabei unterstützt, Daten zu analysieren und in interaktiven Dashboards zu visualisieren. Die Anwendung ermöglicht es Nutzer*innen, auch ohne SQL-Kenntnisse Abfragen durchzuführen und Dashboards und Berichte zu erstellen. Metabase ist mit einer Vielzahl von Datenbanken kompatibel und richtet sich an Anwender*innen, die Daten zugänglich und nutzbar machen möchten.
Man kann Metabase entweder selbst hosten, von einem IT-Dienstleister hosten lassen oder bestehende Hosting-Angebote nutzen:
Vorteile
- ermöglicht eigenständige Exploration von Daten
- zahlreiche Visualisierungstypen
- viele Optionen zur Kommunikation von Ergebnissen: automatsierte Email, Export als Bilddatei oder PDF, Teilen über öffentlichen Link, Einbettung von Dashboards und Grafiken in Website (wie hier)
Nachteile
- Kosten für Hosting relativ hoch
- in der Community Version können Farbpaletten nicht angepasst werden
- erfordert Einarbeitung und Auseinandersetzung mit Datenkonzepten wie z.B. "Joins" (Zusammenführen von Tabellen).
- komplexe statistische Analysen und Modellierungen und spezielle Visualisierungen eher nicht möglich
Fazit
Metabase (und andere BI Tools) sind sinnvoll, wenn ihr mittel- und langfristig eure Daten selbstbestimmt und eigenständig v.a. deskriptiv auswerten wollt. Mit Metabase (und jedem anderen BI Tool) werdet ihr selbst zu Datenanalyst*innen und könnt agil und nach Bedarf neue Visualisierungen und Dashboards anlegen. Komplexe Analysen wie Machine Learning oder KI könnt ihr im Bereich Business Intelligence nicht erwarten. Dafür gibt es nützliche Features, um eure Daten und Datenvisualisierungen mit externen Stakeholdern zu teilen, z.B. über Einbettungen oder öffentliche Links.
Den Vorteilen von Metabase (bzw. BI Tools) stehen nötige Investitionen in Kompetenzaufbau und Infrastruktur gegenüber. Metabase ist ein großes Tool mit vielen Funktionen. Deshalb braucht es Zeit und die Bereitschaft, sich einzuarbeiten und dazuzulernen. Hinzu kommt, dass bestehende Hosting-Optionen nicht günstig sind und Self-Hosting ohne interne Kompetenzen nicht möglich ist. Die Zusammenarbeit mit bestehenden IT-Dienstleistern ist eine Möglichkeit, wird aber natürlich trotzdem etwas kosten.
Insgesamt ist das Investment in ein Business Intelligence Tool nicht für alle CiviCRM-Organisationen notwendig. Es ist aber sehr sinnvoll, wenn Daten perspektivisch für euch eine zentrale Rolle spielen werden.
Anleitungen
Eine Datenbankverbindung in Metabase hinzufügen
Damit Metabase auf die Daten aus eurer Datenbank (z.B. CiviCRM Datenbank oder eine Managed Datenbank) zugreifen kann, müsst ihr eine Verbindung zur Datenbank in Metabase hinzufügen.
- Als Admin in Metabase einloggen.
- Oben rechts auf das Zahnrad → Admin settings klicken.
- Databases wählen → Add a database.
- Datenbank-Typ auswählen (z. B. Postgres, MySQL, SQL Server …).
- Verbindungsdaten eintragen:
- Name
- Host / IP
- Port
- Datenbankname
- Benutzer
- Passwort
- ggf. Connection-String
- Optional: SSL oder SSH-Tunnel aktivieren, falls nötig.
- Save changes (Metabase testet die Verbindung).
- Danach: Sync database schema und ggf. Re-scan ausführen, damit Tabellen/Spalten sichtbar sind.
- Falls Probleme auftreten: Netzwerk/Firewall, Port, DB-Zugriffsrechte und Metabase-Logs prüfen.
In diesem YouTube Video könnt ihr mitverfolgen, wie die Schritte sind. Die schriftliche Dokumentation kann auch hilfreich sein.
Daten auswerten und visualisieren in Metabase
Um eure Daten in Metabase auszuwerten und zu visualisieren, stellt ihr Fragen (en: Questions) an eure Daten. Diese Fragen könnt ihr Sammlungen (en: Collections) oder Dashboards hinzufügen. Einen Überblick über die wichtigsten Metabase-Konzepte findet ihr hier (auf Englisch).
Sammlungen
Sammlungen sind wie Ordner, in denen ihr eure Fragen und Dashboards sortieren könnt.

Fragen
Zentral für die Analyse und Visualisierung von Daten in Metabase sind Fragen (en: Questions). Fragen könnt ihr entweder über mit dem grafischen Query-Editor oder mit SQL "stellen". Wir empfehlen euch, den grafischen Editor zu verwenden. Konzeptionell ähnelt der Editor SearchKit: Man kann Datensätze zusammenfügen, Felder auswählen, Einträge filtern, Daten aggregieren und Kennzahlen auswählen.

- Um eine neue Frage anzulegen, klickt oben rechts den "Neu" Button -> Frage.
- Verwendet die Bedienelemente, um die Daten auszuwählen, zu filtern, ...
- Ihr könnt die Pfeile rechts der Elemente verwenden, um eine Vorschau eurer Frage anzuzeigen.
- Sobald ihr zufrieden seid mit den Daten eurer Frage, klickt auf "Darstellen". Das bringt euch zur Visualisierung eures Ergebnisses.
- Metabase wählt eine passende Visualisierung aus. Ihr könnt eine andere Visualisierung wählen, in dem ihr unten links auf "Visualisierung" klickt und euch durch die Optionen klickt.

Über den Button "Editor" oben rechts könnt ihr jederzeit zurück zum Editor zurückkehren um eure Anfrage anzupassen. Am Ende speichert ihr eure Frage.
Ressourcen: Metabase hat umfassendes Lernmaterial auf der Website, z.B. eine Einführung in "Questions".
Dashboards
In Dashboards könnt ihr eure Fragen zusammen darstellen. Ihr könnt Tabs erstellen, Filter für das ganze Dashboard hinzufügen, Texte und Überschriften einfügen. Ihr könnt direkt neue Fragen in ein Dashboard hinzufügen. Darüber hinaus bieten Metabase Dashboards noch nützliche eingebaute Funktionen wie "Drill-Downs", mit denen man einzelne Daten direkt im Dashboard eingehender explorieren kann.
Ein neues Dashboard erstellt ihr mithilfe des blauen "Neu" Buttons oben rechts.

Eine Einführung zu Dashboards (in Englisch) findet ihr hier. Tiefergehende Tutorials sind im Learn-Bereich zu finden.
Tipp: Wenn ihr Fragen in der Dashboard-Ansicht ändern möchtet (z.B. weil ihr vergessen habt, zu filtern), dann geht das nur, wenn ihr den Dashboard-Editor-Modus über "Speichern" verlasst. Dann könnt ihr die einzelnen Fragen/Visualisierungen über das drei Punkte Dropdown -> Ändere Frage anpassen (siehe Screenshot).

Daten organisieren in Metabase
Wenn ihr feststellt, dass ihr bei der Erstellung von Fragen immer die gleichen Daten zusammenführt, filtert oder berechnet, dann sind die Funktionen Modelle und Metriken einen Blick wert. Modelle sind abgeleitete Tabellen bzw. gespeicherte Fragen, die Daten kuratieren und als Ausgangspunkt für neue Analysen dienen können. Wir haben z.B. ein Modell für "Kontakte" erstellt, welches die Geschlechtsoptionen schon an die Grundtabelle anspielt. So sparen wir uns diesen Schritt bei weiteren Fragen. Mit Metriken erstellt ihr eure Aggregationen nur einmal, speichert sie ab und könnt sie dann immer verwenden.
Alternativen
🔢 daten-auswerten 📊 daten-visualisieren 💬 daten-kommunizieren
Alternativen zu Metabase sind u.a.:
- Apache Superset: komplett Open Source
- Power BI: Business Intelligence Tool in der Microsoft Umgebung
- Tableau: etabliertes BI-Tool aus den USA. Kann auch selbst gehostet werden (Lizenz muss trotzdem erworben werden).
- Looker: BI Tool in der Google Umgebung
Managed Datenbank
Managed Datenbanken sind cloud-basierte Datenbankdienste, bei denen sich der Anbieter um die technische Infrastruktur, Wartung und Skalierung kümmert. Der Anbieter übernimmt Aufgaben wir das Durchführen von automatische Updates oder Backups.
Die Hauptvorteile liegen in der Zeitersparnis durch wegfallende Server-Administration. Nachteile gegenüber dem Self-Hosting sind höhere Kosten, Vendor Lock-in und eingeschränkte Konfigurationsmöglichkeiten.
Im Kontext der Visualisierung und Analyse von CiviCRM-Daten können managed Datenbanken als sogenanntes Data-Warehouse zum Einsatz kommen. Ein Data-Warehouse ist eine Datenbank, die speziell für Analysen und Berichte optimiert ist und Daten aus verschiedenen Quellen sammelt und strukturiert.
Wir konzentrieren uns in diesem Projekt auf relationale Datenbanken mit SQL (Structured Query Language). Relationale Datenbanken organisieren Daten in Tabellen mit Zeilen und Spalten, ähnlich wie Excel-Tabellen. Die Tabellen können über gemeinsame Spalten (Keys) miteinander verknüpft werden. SQL ist die Standardsprache für das Abfragen und Verwalten dieser Datenbanken.
Serverless Datenbanken
Serverless ist eine spezielle Form von Managed Datenbanken mit zusätzlichen Vorteilen. Normalerweise bezahlt man bei managed Datenbaken für die permanente Nutzung eines Servers, auf der die Datenbank läuft. Wie der Name beschreibt, fällt dies bei serverless jedoch weg. Konkret bedeutet das Pay-per-Use-Bezahlung nur für tatsächlich verbrauchte Ressourcen und die Möglichkeit des “Cold Start”. Dies bedeutet, dass die Datenbank bei Inaktivität pausieren und bei Bedarf reaktiviert werden kann.
Bei der Nutzung eine Datenbank als externes Data Warehouse wird diese typischerweise nicht kontinuierlich abgefragt, sondern hauptsächlich für periodische Berichte und Analysen genutzt. Serverless bietet daher Kosteneffizienz bei unregelmäßiger Nutzung.
Grafische Nutzeroberfläche statt SQL
SQL schreiben zu können ist ein nützlicher Skill; es zu lernen erfordert jedoch Zeit. Eine Alternative ist die Verwaltung einer Datenbank über grafische Nutzeroberflächen.
Moderne managed Datenbanken bieten oft webbasierte Oberflächen, die es ermöglichen, Tabellen zu erstellen, Daten einzufügen und anzuzeigen, ohne SQL-Code schreiben zu müssen. Diese Oberflächen funktionieren ähnlich wie Excel und reduzieren die Einstiegshürde erheblich. Gleichzeitig bleibt die Option bestehen, bei Bedarf auf SQL-Befehle zurückzugreifen.
Neon
Neon ist eine serverless PostgreSQL-Datenbank, die sich komplett im Browser über eine intuitive GUI verwalten lässt. Wir haben uns bei unseren Experimenten für die Nutzung Neon entschieden, weil es serverless ist und gleichzeitig eine benutzerfreundliche Weboberfläche bereitstellt.

Vorteile
- GUI-Management: Tabellen können direkt im Browser erstellt und verwaltet werden
- PostgreSQL: Vollständig kompatibel mit dem weit verbreitenden SQL-Flavor Postgres
- Automatische Backups und Sicherheit
- Kostenloser Plan für kleinere Projekte verfügbar
- Datenbanken können in der EU betrieben werden
Nachteile
- Nicht Open Source
- Bei sehr intensiver Nutzung können Kosten steigen
- Weniger Kontrolle über die Infrastruktur (Neon nutzt AWS oder Azure in der EU)
Betrieb
Neon eignet sich besonders gut für CiviCRM-Analysen, da die Datenbank typischerweise nicht kontinuierlich abgefragt wird, sondern hauptsächlich für periodische Berichte und Analysen genutzt wird. Die serverless Architektur und die EU-Verfügbarkeit machen es zur idealen Lösung für deutsche Organisationen.
Anlegen einer Datenbank und Tabelle
Arbeite dich durch das Neon Setup bis zu Onboarding. Nun steht dir eine Datenbank zur Verfügung!
Hier wird erklärt wie Neon im Browser bedient werden kann und Tabellen erstellt werden können. Für die Erstellung von Tabellen kann auch der SQL Editor verwendet werden.
Alternativen
Supabase
Supabase bietet ähnliche Funktionen wie Neon, ist jedoch mehr auf Echtzeitanwendungen ausgerichtet und nicht serverless.
Scaleway Serverless SQL
Scaleway ist ein französischer Anbieter einer umfangreichen Zahl an Cloud-Angeboten, bietet jedoch für serverless Datenbanken eine weniger umfangreicherer GUI als Neon.
Workflow Automation Tools
🔢 daten-auswerten
🧹 daten-organisieren
Workflow Automation Tools sind browserbasierte Anwendungen, über die man einzelne Schritte, wie das Laden, Senden und Verarbeiten von Daten direkt miteinander verknüpfen und automatisieren kann. Viele Workflow Automation Tools sind dabei nicht auf Daten spezialisiert, sondern es lässt sich Beliebiges verknüpfen und automatisieren. Auf Daten bezogen lassen sich diese Tools auch dem Feld der Data Orchestration zuordnen. Wir legten jedoch den Fokus auf Tools, die primär über eine zugängliche graphische Nutzungsoberfläche funktionieren, was bei vielen dedizierten Data Orchestration Tools, die oft als Paket für Programmiersprachen wie Python existieren, oft nicht der Fall ist.
Gemeinsam ist diesen Tools, dass Aktionen in Schritten, oft Knoten genannt, durchgeführt werden. Knoten erhalten Inputs und produzieren Outputs, die wiederum zu Inputs eines anderen Knoten werden können. So entsteht sowohl mit Bezug auf die Reihenfolge der Ausführung, also auch mit Bezug auf den Fluss der Daten ein Pfad bzw. Flow. Ein verwandtes Konzept ist das des DAG (Directed acyclic graph).
Workflow Automation Tools sind hilfreich, um Prozesse wie Datenexporte oder Verarbeitung nicht wiederholt zeitaufwendig manuell erledigen zu müssen. Gleichzeitig sind sie eine Alternative dazu, Automatisierungen komplett selbst zu programmieren. Somit sind sie zugänglicher für Daten-Anfänger:innen bzw. Menschen, die Skills in anderen Bereichen haben. Oft ist jedoch der Modus, dass man standardmäßig Flows mit Klicken baut, jedoch wenn man es für sinnvoll erachtet, in den Knoten mit Programmieren arbeiten kann.
Die folgende Tabelle zeigt eine unvollständige Übersicht (Stand 23.09.2025) über solche Tools und verdeutlicht deren Vielzahl.
| Name | Website | Vollständig OSS | Kostenloser Plan | SaaS-Preis ab (monatlich) | Komplexität Selbst-Hosting (1–10) | DSGVO-Hinweise SaaS | Konfig. mit GUI | Konfig. mit Code | Git-basiert | Allgemeine Hinweise |
|---|---|---|---|---|---|---|---|---|---|---|
| Pipedream | https://pipedream.com | Nein | Ja | $49 | – | Unklar: Privacy & Security (GDPR) | Ja | Ja | Nein | KI-Pipeline-Builder-Assistent |
| n8n | https://n8n.io/ | Ja | Nein | $24 | 3 | Azure in Frankfurt: GDPR | Ja | Ja | – | – |
| Kestra | https://kestra.io/ | Ja | Nein | Enterprise (unbekannt) | 4 | – | Nein | Ja | Ja | Komplex mit YAML für nicht-technische Anwender |
| Zapier | https://zapier.com/ | Nein | – | $30 | – | – | – | – | – | – |
| Automatisch | https://automatisch.io | Ja | Ja | $20 | – | – | – | – | – | Begrenzter SQL-Adapter (nur Postgres, wenige Funktionen) |
| Make | https://www.make.com | Nein | Ja | $0 / $9 | – | AWS in der EU: Make Sub-Processors (Juni 2025) | – | – | – | Auswählen, dass in EU gehostet |
| KNIME | https://www.knime.com | Nein | – | – | – | – | – | – | – | – |
| Activepieces | https://www.activepieces.com/ | Ja | Ja | $25 | – | Keine Informationen gefunden | – | – | – | – |
| Rudderstack | https://www.rudderstack.com/ | Ja | – | – | – | – | – | – | – | Wahrscheinlich zu vertriebsorientiert |
In diesem Projekt haben wir uns für das Testen von n8n und Kestra entschieden, da wir Priorität auf Open Source, die Möglichkeit zum Self-Hosting und ausreichende Funktionen für Data Orchestration legten.
n8n
Im Repository findet ihr in dem Ordner supporting_code/n8n_flows Flows, die ihr in eure n8n-Instanz importieren könnt.
Vorteile
- Intuitive Klick-Umgebung
- Große Community
Nachteile
- Begrenzte Programmierumgebung
Kestra
Im Repository findet ihr in dem Ordner supporting_code/kestra_flows Beispiel-Flows dafür, wie ihr Daten über die API oder die Datenbank laden und weitersenden könnt.
Vorteile
- Quasi unbegrenzte Möglichkeiten und viele Wege ein Problem zu lösen
- Flows liegen als Datei (yaml) vor und können so leicht persistiert werden
Nachteile
- Unbekannter als andere Tools
- Viele Probleme lassen sich nur mit Programmieren lösen
- Umständlich, Änderungen in Flows zu testen
Python und R
Große Teile dieses Abschnitts wurden von ChatGPT erstellt und dann inhaltlich und redaktionell überarbeitet und ergänzt.
Mit Programmiersprachen wie Python und R lässt sich im Prinzip alles umsetzen, was man für die Analyse und Visualisierung braucht.
Ähnlich wie bei SQL: Coden ist ein nützlicher Skill, es zu lernen erfordert jedoch Zeit. Deswegen sind Workflow Automation Tools oder andere grafische Nutzeroberflächen eine nützliche Alternative. Selbst geschrieben Skripts und Programme erfordern außerdem oft spezielle Maintenance und können Abhängigkeiten zu Entwickler:innen herstellen.
Python
🔢 daten-auswerten 📊 daten-visualisieren 💬 daten-kommunizieren 🧹 daten-organisieren
Python ist eine sehr vielseitige und populäre Programmiersprache. Mit Python könnt ihr Daten aus CiviCRM abrufen, transformieren, analysieren und in interaktiven Dashboards oder Notebooks darstellen.
Datenintegration mit CiviCRM
Python bietet verschiedene Möglichkeiten, um auf CiviCRM-Daten zuzugreifen:
- API-Anbindung: Mit Bibliotheken wie requests oder httpx können direkt API-Anfragen an CiviCRM gestellt werden.
- Datenimport: Mit pandas können CSV- oder JSON-Exporte aus CiviCRM eingelesen und weiterverarbeitet werden.
- Automatisierung: Skripte können regelmäßig ausgeführt werden, um Daten aktuell zu halten.
Beispiele dafür, wie ihr die API in Python nutzen könnt, findet ihr im Repository in den Ordnern supporting_code/notebooks und supporting_code/test_data. Letzteres ist der Code, den wir für die Erstellung von Testdaten verwendet haben.
Analyse und Visualisierung
Für die Analyse und Visualisierung von CiviCRM-Daten stehen zahlreiche Bibliotheken zur Verfügung:
- Interaktive Dashboards und Anwendungen: Mit dash, streamlit, Quarto oder Marimo können interaktive Dashboards bzw. kleine Datenanwendungen erstellt werden.
- Notebooks & Berichte: Marimo, Jupyter Notebooks, JupyterLab oder Quarto ermöglichen eine interaktive Datenanalyse und Dokumentation in einem Dokument. Aus diesen Dokumenten können PDF- oder HTML-Berichte/Reports erstellt werden. Letztere bieten abhängig vom gewählten Tool und der genauen Implementation ein gewisses Maß an Interaktivität.
- Datenanalyse: pandas und numpy ermöglichen komplexe Datenanalysen, Filterungen und Transformationen.
- Statistische Analysen: scipy und statsmodels bieten erweiterte statistische Funktionen.
- Visualisierung: matplotlib, seaborn und plotly helfen, Daten in ansprechenden Grafiken darzustellen.
Potenziell interessante Frameworks und Tools
- pandas – Datenanalyse und -manipulation
- numpy – Numerische Berechnungen
- matplotlib – Grundlegende Visualisierungen
- seaborn – Statistische Datenvisualisierung
- plotly – Interaktive Visualisierungen
- dash – Interaktive Dashboards
- streamlit – Schnelle Erstellung von Web-Apps für Daten
- Jupyter Notebooks – Interaktive Datenanalyse und Dokumentation
Fazit
Python ist eine sehr gute Wahl, wenn ihr CiviCRM-Daten nicht nur analysieren, sondern auch in automatisierte Prozesse, interaktive Dashboards oder Webanwendungen integrieren wollt. Die Sprache bietet eine große Flexibilität und viele Tools für Datenanalyse, Visualisierung und Automatisierung. Wenn ihr bereits mit Python arbeitet oder eine skalierbare Lösung für komplexe Datenanalysen sucht, ist Python richtig für euch.
Leider war es im Rahmen des Datenvorhabens zeitlich nicht möglich, die zahlreichen und vielfältigen Umsetzungsmöglichkeiten von Python in einem angemessenen Umfang zu erkunden. Deswegen haben wir uns dagegen entschieden, konkrete Ansätze mit Python vorzustellen. Wenn ihr Interesse an Python habt, schaut gerne in der Datensprechstunde vorbei und wir besprechen eure konkreten Fragen und Anforderungen!
R
🔢 daten-auswerten 📊 daten-visualisieren 🧹 daten-organisieren
R ist eine Programmiersprache und Umgebung, die speziell für statistische Datenanalyse und Visualisierung entwickelt wurde. Sie eignet sich hervorragend für die Integration, Analyse und Darstellung von CiviCRM-Daten, insbesondere wenn statistische Auswertungen im Vordergrund stehen.
Datenintegration mit CiviCRM
R bietet verschiedene Pakete, um Daten aus CiviCRM zu importieren und zu verarbeiten:
- API-Anbindung: Mit Paketen wie httr oder curl können direkt API-Anfragen an CiviCRM gestellt werden.
- Datenimport: Pakete wie readr oder jsonlite ermöglichen das Einlesen von CSV- oder JSON-Dateien aus CiviCRM.
- Automatisierung: R-Skripte können regelmäßig ausgeführt werden, um Daten zu aktualisieren.
Analyse und Visualisierung
R bietet eine Vielzahl von Paketen für die Analyse und Visualisierung von Daten:
- Datenanalyse: dplyr und tidyr ermöglichen das Bereinigen, Transformieren und Analysieren von Daten.
- Statistische Analysen: R bietet eine breite Palette an Paketen für statistische Analysen, darunter stats und ggplot2.
- Visualisierung: ggplot2 ist eines der mächtigsten Pakete für Datenvisualisierung und ermöglicht die Erstellung hochwertiger Grafiken.
- Interaktive Dashboards: Mit shiny können interaktive Webanwendungen und Dashboards erstellt werden.
- Notebooks: R Markdown und RStudio ermöglichen die Erstellung von interaktiven Berichten und Notebooks, die Analyse und Dokumentation kombinieren.
Potenziell interessante Pakete und Tools
- RStudio – Entwicklungsumgebung für R
- Quarto oder RMarkdown – Interaktive Berichte, Dashboards und Notebooks
- shiny – Interaktive Dashboards und Web-Apps
- tidyverse Packages: Sammlung von aufeinander abgestimmten Packages, die Datenmanipulation, Datenbereinigung (u.a.
dplyr,tidyr) und Datenvisualisierung (ggplot2) in R ermöglichen. - httr – API-Anfragen
- jsonlite – JSON-Datenverarbeitung
Fazit: R
R ist die beste Wahl, wenn euer Fokus auf statistischen Analysen und hochwertigen Visualisierungen liegt. Die Sprache bietet viele Pakete für Datenanalyse und -darstellung, insbesondere für wissenschaftliche oder detaillierte statistische Auswertungen. Mit Tools wie shiny, Quarto und RMarkdown könnt ihr interaktive Berichte und Dashboards erstellen; mit ggplot könnt ihr eure Daten visualisieren.
Leider war es im Rahmen des Datenvorhabens zeitlich nicht möglich, die zahlreichen und vielfältigen Umsetzungsmöglichkeiten von R in einem angemessenen Umfang zu erkunden. Deswegen haben wir uns dagegen entschieden, konkrete Ansätze mit R vorzustellen. Wenn ihr Interesse an R habt, schaut gerne in der Datensprechstunde vorbei und wir besprechen eure konkreten Fragen und Anforderungen!
Self-Hosting
Für einige der genannten Tools gibt es die Option, diese selbst zu hosten. Das bedeutet, das man mehr oder weniger selbst für den Betrieb und das Aufsetzen verantwortlich ist. Doch auch hier gibt es Möglichkeiten, die den Aufwand und die notwendigen Fähigkeiten minimieren. Einige davon sollen hier aufgelistet werden.
- Elestio, z.B. für Kestra
- Coolify, z.B. für Metabase
- Civioneclick für CiviCRM
Andere Visualisierungstools
Neben Business Intelligence Tools, Tabellenkalkulationsprogrammen (Excel, Google Sheets) und Programmiersprachen gibt es auch viele andere Tools, in denen Daten visualisiert werden können. Einige, die uns inzwischen häufiger untergekommen sind, nennen wir hier.
Die Tools unterscheiden sich danach, ob sie primär Datenvisualisierung als Zweck haben oder ob dies eine von vielen Funktionen ist.
Primär Datenvisualisierung:
- Datawrapper: etabliertes Datenvisualisierungstool aus Berlin, populär im Journalismus. Fokus auf die Einbettung von interaktiven Grafiken in Webseiten.
- flourish: relativ neues Datenvisualisierungstool, gehört zu Canva (s.u.). Viele Visualisierungsmöglichkeiten, die in Webseiten eingebettet werden können.
Weniger geeignet für Verwendung im Teamkontext, aber gut zum niedrigschwelligen Experimentieren:
- Scimago Graphica: No-Code Tool, welches lokal installiert wird (keine WebApp). Keine Live-Anbindung an Datensätze möglich.
- RawGraphs: browserbasiertes, datenschutzfreundliches (kein Account; Daten werden im Browser verarbeitet) Open-Source-Tool rein zur einmaligen Erstellung von Visualisierungen.
Datenvisualisierung als Funktion:
- Canva ist primär ein Tool zur Erstellung visueller Inhalte. In Canva können auch direkt Datenvisualisierungen erstellt werden. Mehr dazu hier.
Wir konnten diese Tools im Rahmen dieses Datenvorhabens nicht in unseren Experimenten berücksichtigen. Vor allem Datawrapper, flourish und Canva sind jedoch aufgrund ihres grundsätzlich webbasierten Ansatzes gut anschlussfähig an hier vorgestellte Tools und Ansätze (siehe z.B. Infokasten hier zur Verwendung von Google Sheets als Datenquelle für Visualisierungstools).
Fazit
Durch die verstärkte Förderung von Open-Source-Lösungen wie CiviCRM, insb. durch die Deutsche Stiftung für Engagement und Ehrenamt, ist die deutschsprachige CiviCRM-Community in den vergangenen Jahren noch aktiver und stärker geworden1. Mehr und mehr Organisationen pflegen Daten in CiviCRM und wollen sie über das Management ihrer Arbeitsabläufe - sei es die Koordination von Ehrenamtlichen, die Pflege von Kontakten oder das Management von Spenden und Förderanträgen - hinaus nutzen.
In diesem Datenvorhaben haben wir uns der Frage gewidmet: Wie können zivilgesellschaftliche Akteur*innen CiviCRM-Daten analysieren und visualisieren? Unsere Recherchen und Experimente haben gezeigt, dass es vielfältige Möglichkeiten gibt, um CiviCRM-Daten zu analysieren und zu visualisieren: die Verwendung von internen Tools wie SearchKit und ChartKit, der Anschluss von BI-Tools wie Metabase, der Import von CiviCRM-Daten in Excel / Google Sheets, ETL-Pipelines oder verschiedene Lösungen in Python oder R. Wichtig ist: Alle Tools und Ansätze haben ihre Vor- und Nachteile - es gibt kein eindeutiges Richtig oder Falsch. Die beste Lösung hängt von den Bedarfen, Anforderungen und Ressourcen der einzelnen Organisation ab.
Erkenntnisse und Empfehlungen
Datenanalyse und -visualisierung in CiviCRM ist möglich - eigene Erwartungen managen und Bedarfe realistisch einschätzen
CiviCRM ist primär ein CRM zur Organisation von Prozessen und Kontakten. Das bedeutet, dass CiviCRM-interne Tools zur Analyse und Visualisierung von Daten (verständlicherweise) nicht so flexibel, umfassend und mächtig sind wie dedizierte Tools. Die Implementation von CiviCRM-internen Tools und Workflows ist allerdings im Vergleich zur Verwendung von zusätzlichen Tools relativ niedrigschwellig und kosteneffizient umsetzbar. Die Beschränkung auf einen CiviCRM-internen Setup kann ausreichend sein, ...
- ... wenn es wichtig ist, dass Analysen und Visualisierungen direkt in CiviCRM verfügbar sind.
- ... wenn die Zielgruppe der Analysen (z.B. ehrenamtlicher Vorstand) selbst Zugang zu CiviCRM hat und es selbstständig navigieren kann.
- ... wenn Analysen und Visualisierungen nur punktuell (z.B. für einen Jahresbericht) benötigt werden und manuelle Prozesse (z.B. Exporte, einmalige Aufbereitung in Excel) keine große Belastung darstellen.
- ... wenn Ansprüche an statistische Tiefe und Design der Visualisierungen eher niedrig sind (deskriptive Auswertungen, Kreuztabellen; geringe Anpassungen bei Visualisierungen)
➡️ Empfehlung: NPOs sollten ehrlich für sich evaluieren, wie viel, wie tiefgehend, wie oft und für wen sie ihre CiviCRM-Daten auswerten und visualisieren wollen, können und müssen. Alle relevanten internen Stakeholder sollten in diesen Prozess miteinbezogen werden, um zu einem gemeinsamen Verständnis zu gelangen, ob die Möglichkeiten von CiviCRM "good enough"2 für alle sind.
Potenziale von SearchKit noch nicht ausgeschöpft
SearchKit hat ein großes Potenzial: sowohl für Analysen direkt in CiviCRM, aber auch zur DSGVO-freundlichen Aggregation von personenbezogenen Daten vor einem Export der Ergebnisse in ein anderes Tool mithilfe der CiviCRM API. In unseren Gesprächen haben wir den Eindruck gewonnen, dass die Verwendung von SearchKit für viele Nutzer*innen leider noch nicht zugänglich genug ist. Auch wenn Akteur*innen konkrete Unterstützung in der Software-für-Engagierte Community finden können, fehlt an anfängerfreundlichen Schulungen und Materialien (insb. deutschsprachigen), die es nicht-technischen Nutzer*innen ermöglicht, die hinter SearchKit liegenden SQL-Konzepte (Filter, Group-By, Summarize, Joins) und Datenstrukturen zu verstehen.
➡️ Empfehlung: NPOs, die viel mit CiviCRM arbeiten und ihre Daten mittelfristig in CiviCRM analysieren und aggregieren wollen (auch zur Weiterverwendung in anderen Tools), sollten in das Lernen von SearchKit und ChartKit investieren (z.B. CiviCRM Academy). CiviCRM-Dienstleister*innen könnten offene Workshops und Schulungen für SearchKit anbieten. Die strukturierte Aufarbeitung von Wissen durch die CiviCRM-Community selbst sollte gefördert werden, um Kompetenzen zur eigenständigen Analyse von Daten in CiviCRM zugänglich zu machen.
BI-Tools ermöglichen selbstbestimmteres Analysieren und Visualisieren von Daten, sind aber keine Allzwecklösung
Der Einsatz von Business-Intelligence-(BI)-Tools erlaubt es Nutzer*innen, Daten aus CiviCRM mit anderen Daten zu verknüpfen und sich eigenständig, agil und kontinuierlich verschiedene Analysen, Visualisierungen und Dashboards zu erarbeiten, die visuell ansprechender, interaktiver und analytisch tiefergehender sind als bei ChartKit & Co.
Dennoch ist ein BI-Tool keine Allzwecklösung: Bei komplexen statistischen Analysen oder sehr spezifischen Visualisierungsbedarfen (z.B. Data Storytelling für einen Pitch) stoßen sie an ihre Grenzen. Hier kann ein spezialisiertes Visualisierungstool eine gute Ergänzung sein. Auch gibt es je nach Tool und Pricing-Modell Einschränkungen im Funktionsumfang.
➡️ Empfehlung: NPOs, für die Daten und deren Analyse einen hohen strategischen Stellenwert für die eigene Steuerung und Organisationsentwicklung hat und bei denen Personen regelmäßig und eigenständig Daten analysieren und visualisieren, sollten sich mit BI-Tools auseinandersetzen. Individuelle Kompetenzen und Arbeitsgewohnheiten sowie Anforderungen und Zielgruppen der konkreten Auswertungen sind entscheidend dafür, ob ein BI-Tool gut zu den Bedarfen passt.
Die Integration von CiviCRM und BI-Tools erfordert in der Regel technisches Know-how und den Anschluss eurer CiviCRM-Daten. Die CiviCRM-Dienstleister, mit denen wir sprechen konnten (civilisten, flyingcivi), zeigten sich hier offen und erfahren in ähnlichen Projekten. Für den Betrieb eines BI-Tools müssen jedoch finanzielle Ressourcen (z.B. für Lizenzen oder Server) und zeitliche Kapazitäten für Kompetenzaufbau vorhanden sein.
Die CiviCRM-API eröffnet einen großen Lösungsraum – erfordert allerdings technisches Verständnis
Die CiviCRM-API eröffnet viele Möglichkeiten, um Daten zu exportieren, zu verknüpfen oder automatisiert weiterzuverarbeiten. Vielversprechend erscheint der Import von CiviCRM-Daten in Tabellenkalkulationsprogramme wie Excel und Google Sheets, sollte jedoch bedacht eingesetzt werden. Grafische Schnittstellen-Tools (GUI-Tools) machen API-basierte Prozesse zugänglicher. Besonders leistungsfähig sind Lösungen mit Python oder R. Diese setzen jedoch eine gewisse IT-Infrastruktur und Wartungskompetenzen und -kapazitäten voraus, um langfristig Wirkung zu entfalten.
Für alle Nutzungsszenarien ist ein grundlegendes Verständnis von APIs, Datenstrukturen und Datenflüssen notwendig. Auch Fragen in Bezug auf Datenschutz und Datensicherheit sind von zentraler Bedeutung.
➡️ Empfehlung: Akteur*innen, die viel Zeit in manuellen Export- und Importprozessen von/zu Excel & Co. verlieren, können prüfen, ob sie diese mithilfe der API punktuell selbst automatisieren können. Hier gibt es Potenzial für erste kleinere "Quick Wins". Auch für umfassendere, dauerhafte Datenintegrationen von CiviCRM-Daten ist die API der "Schlüssel" – hier sollten Organisationen jedoch strategisch und strukturiert vorgehen: sich selbst einarbeiten3, Projekte gut planen4 und Zugang zur nötigen Expertise sicherstellen.
Nutzer*innen nicht alleine lassen
Die Analyse und Visualisierung von CiviCRM-Daten ist kein triviales Unterfangen und erfordert die Auseinandersetzung mit strategisch-organisatorischen Fragestellungen und z.T. die Einarbeitung in (neue) technische Konzepte und Tools. Das ist für viele Organisationen eine Herausforderung – meist fehlt es an Zeit, Personal, Geld oder technischer Unterstützung. Mit diesem Material wollten wir zeigen, welche Wege und Tools es gibt, um CiviCRM-Daten besser zu nutzen. Unterstützungsstrukturen wie das Civic Data Lab, CorrelAid oder die Software-für-Engagierte-Community sind essenzielle Anlaufpunkte um Wissen zu teilen und gemeinsam erste Schritte zu gehen.
Kommt gerne in unsere Datensprechstunde oder schreibt uns eine Mail!
-
Beispiel: Software-für-Engagierte Forum ↩
-
Alle wollen tolle Datenvisualisierungen mit eigenen Farben und Schriftarten. Aber ist es der Aufwand - zeitlich, finanziell, ... - wirklich wert oder reicht doch die nicht ganz so schöne ChartKit-Grafik? ↩
-
Erklärungen von Begriffen wie API, Server etc. gibt es im Selbstlernmaterial des Civic Data Labs ↩
-
z.B. mit unserer interaktiven Planungshilfe für Datenvorhaben ↩
Über das Datenvorhaben
Die Inhalte dieser Seite wurden von Jonas Stettner und Leo Preu (beide CorrelAid e.V., tätig im Civic Data Lab) erstellt. Zum Teil haben LLMs die beiden bei der Recherche, Übersetzung und Formulierung unterstützt. Wenn signifikante Teile von Seiten oder Sektionen von LLMs geschrieben sind, haben wir dies separat gekennzeichnet.
Diese Seite sowie Code und Dateien der Experimente finden sich in einem GitHub Repository.
Limitationen des Datenvorhabens
CiviCRM ist ein mächtiges und komplexes Tool und wir sind weder CiviCRM- noch Fundraising- oder CRM-Expert*innen. Deshalb kann es sein, dass uns vielversprechende Optionen aus dem Civi-Universum entgangen sind. Dies gilt v.a. für fachspezifische CiviCRM-Erweiterungen - wir hatten leider nicht die Zeit, um uns tiefergehend mit allen Anwendungsfällen (Fundraising, Freiwilligenmanagement, …) und den dazugehörigen Erweiterungen auseinanderzusetzen.
Unsere Experimente haben wir mit unserer selbst gehosteten Basisinstallation von CiviCRM 6.4.0. durchgeführt. Zwischen der Standalone-Version von CiviCRM und dessen Nutzung in Kombination mit CMS wie Drupal oder Wordpress gibt es Unterschiede. Auch Spezifika von Hosting-Anbietern (z.B. Systopia-eigene Extensions) konnten wir nicht berücksichtigen. Über Beiträge zu dieser Dokumentation von Personen, die in diesen Bereichen mehr Ahnung haben, würden wir uns sehr freuen.
In der Bearbeitung der Use Cases waren wir inhaltlich beschränkt durch unsere selbst erstellten Testdaten. Wir hatten Kontakte und Zuwendungen, aber keine Events oder Aktivitäten wie Eventteilnahmen o.ä.
Lizenz
![]()
- Attributionsvorschlag: ”CiviCRM Datan analysieren und visualisieren” von Leo Preu (CorrelAid e.V. / Civic Data Lab) und Jonas Stettner (CorrelAid e.V. / Civic Data Lab), abgerufen am DATUM. Lizensiert unter CC-BY 4.0.
- Attributionsvorschlag für einzelne Abschnitte / Unterseiten: ”[Unterseite]” in ”CiviCRM Datan analysieren und visualisieren” von Leo Preu (CorrelAid e.V. / Civic Data Lab) und Jonas Stettner (CorrelAid e.V. / Civic Data Lab), abgerufen am [Datum]. Lizensiert unter CC-BY 4.0.
Beitragen
Du möchtest etwas beitragen zu dieser Website? Darüber freuen wir uns sehr!
Wenn du dich mit Git, GitHub und Markdown auskennst, freuen wir uns über einen Issue und dazugehörigen Pull Request im GitHub Repository. Du hattest beim Lesen des vorherigen Satzes nur Fragezeichen und innere “hä?” Momente? Gar kein Problem! Schreib uns gern eine Email an leo.p@correlaid.org mit deinen Erkenntnissen. Wir kümmern uns dann um die Online-Stellung!
Wie nutzt die Zivilgesellschaft CiviCRM?
Im Sinne der partizipativen Technikgestaltung haben wir im Rahmen des Datenvorhabens schriftlich und in persönlichen Gesprächen Meinungen, Bedarfe und Anfoderungen von zivilgesellschaftlichen CiviCRM-Nutzer*innen eingeholt. Wir danken allen, die mit uns ihre Anliegen geteilt haben. Es zeigte sich, dass es eine große Varianz gibt - in der Nutzung von CiviCRM, aber auch in den Wünschen und Anforderungen an Auswertungen der eigenen Daten.
Welche Daten pflegen Organisationen in CiviCRM?
Standardmäßig nutzen zivilgesellschatliche Organisationen CiviCRM für Kontakte (Personen, Organisationen), häufig auch für Mitgliederverwaltung, Spendenmanagement oder Veranstaltungsmanagement.
Speziellere Anwendungsfälle sind z.B.:
- Fördermittel/Fondsverwaltung
- Case-/Projektmanagement und Aktivitäten
- Engagement-/Integrationsdaten
- Kampagnen- und politische Arbeit
Welche Auswertungen wären besonders hilfreich?
- Finanz- und Spendenberichte: Entwicklung von Spendenaufkommen, Zusammensetzung (Dauer-/Einzelspenden), Verknüpfung mit Aktivitäten.
- Fördermittelmonitoring: Anzahl und Volumen bewilligter Projekte, regionale Verteilungen, Vergleich nach Zielgruppen.
- Mitglieder- und Verbandsentwicklung: Entwicklung nach Region, Alter, Interessen, Potenziale für Beitragsmodelle.
- Veranstaltungen & Engagement: Teilnahmestatistiken, Übergang von Veranstaltungen ins Ehrenamt, Bindungs- und Austrittsgründe.
- Politische Kommunikation: Datenaufbereitung für Sachberichte, Evaluationen, Präsentationen an Ministerien, Fördergeber oder Öffentlichkeit.